
Pod의 생명주기
Pod는 kubelet에 의해 생성되며, 영구적인 엔티티가 아니라 일시적인 엔티티이다. Pod이 생성되면 UID를 할당받고, node에 스케줄링 되어서 할당된 node 내에서 종료될때까지 남아있는다. Pod은 한번 스케줄링 되어 node에 할당되면 그걸로 끝이라서 일시적이라고 할 수 있는 것이다. 즉, 같은 Pod이 rescheduling 되는 일은 없다. 또한 Pod은 생성되어서 종료될때까지 생명주기를 가진다
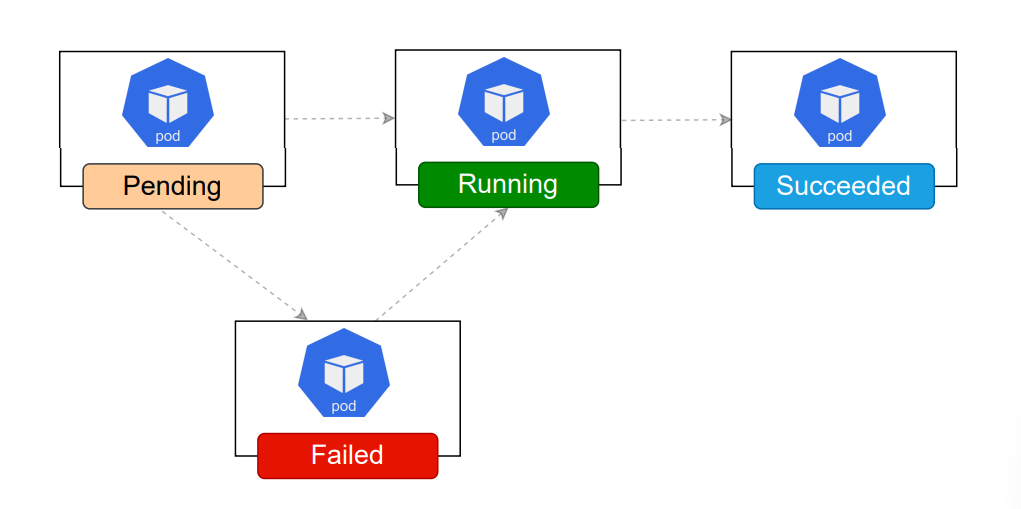
| Pending | Pod이 kube scheduler에 의해서 스케줄링 되기 이전 상태이다. Registry 에서 Image를 pull해오면서 준비하는 상태. 즉, Pod이 만들어지는 단계이다. |
| Running | Pod이 만들어져서 Node에 할당이 된 상태이다. Pod 내부서는 하나 이상의 Container 가 실행되고 있다. |
| Succeeded | 모든 컨테이너가 정상적으로 종료되는 상태이다. |
| Failed | 모든 컨테이너가 종료된 상태이지만, 하나 이상의 컨테이너가 비정상적으로 종료된 상태이다. |
| Unknown | Pod의 상태가 어떤 상태인지 알 수 없을 수 있다. Unknown 상태는 주로 Pod이 running 되어야 하는 Node와 통신할 때 에러가 일어나는 경우 발생한다고 한다. |
추가적으로, Pod이 종료될때는 OS에서 Process가 종료될 때처럼, exit(code) 코드 반환 값에 따라 정상 종료가 되었는지 판단할 수 있다. 0을 return하는 경우 정상종료, non-zero를 return 하는 경우 비정상 종료라는 의미이다.
또한 Pod이 삭제될 경우 kubectl 명령어에 의해서 Terminating이라고 표시될 수도 있는데, 이 Terminating은 Pod의 상태에 해당하지 않는다고 한다. Pod이 안전하게 종료되기 위해서 기본 30초정도 딜레이 시간이 있고나서 삭제되므로 이 순간을 표시하는 것이며 상태에 해당하지는 않는다.
실제로 pod의 상태를 확인해보려면 kubectl get pods 명령어로 확인할 수 있다.
vagrant@kube-control1:~/work/mj$ kubectl get pods
NAME READY STATUS RESTARTS AGE
example-pod 1/1 Running 0 8s컨테이너의 상태
하나의 Pod에는 하나 또는 다중 컨테이너로 구성되어있다. Pod이 스케줄링되어 실행된다는 의미는 Pod 내부의 컨테이너들이 실행된다는 의미이며, kubelet은 컨테이너의 상태를 주기적으로 체크한다.
컨테이너의 상태는 다음과 같다.
| Waiting | 컨테이너 시작 전 Image pull 또는 Storage 연결 등 필요한 작업을 하는 상태이다. |
| Running | 컨테이너가 실행 중인 상태이다. |
| Terminated | 컨테이너의 실행이 완료된 상태 |
컨테이너 상태 확인하기
$ kubectl get pods example-pod -o json다음 명령어를 통해 status 필드 하위의 containerStatuese 필드 안의 state 필드를 확인해보면 상태 정보를 확인할 수 있다.
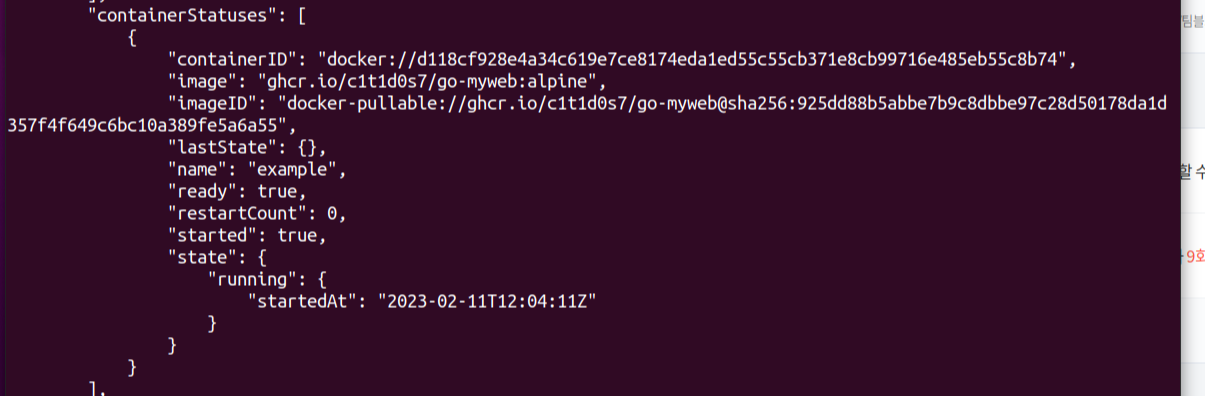
또는 명령어로 바로 상태값을 출력할 수 있다.
$ kubectl get pod example-pod -o jsonpath='{.status.containerStatuses[*].state}'

컨테이너 재시작 정책 (Restart Policy)
위에서 kubelet이 컨테이너의 상태를 체크한다고 했는데, 쿠버네티스에서는 컨테이너에 오류가 발생하는 경우 컨테이너를 재시작 하는 정책이 있다. 이를 Restart Policy라고 하며 따로 설정해 주지 않는다면 Always 값으로, 오류 발생시 항상 재시작을 시도 한다는 의미이다. 재시작 정책에는 Always(항상), Onfailure (실패 시 재시작, 정상종료시 재시작 하지 않음), Never (재시작 안함) 세가지 정책이 있다.
Manifest File에 재시작 정책에 대한 설정을 할 수 있다.
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
restartPolicy: Always
containers:
- name: example
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
protocol: TCP또한 재시작을 할 때 kubelet은 exponential back-off delay (지수 백오프 지연시간)을 따라서 delay 시작을 주고 재시작을 한다. 지수 백오프 지연시간이란 한번 컨테이너에 문제가 있을 때 10초, 20초, 40초... 로 지수만큼 증가시키며 재시작을 시도해 보는 것이다. 지연시간이 10분 이상을 넘게되면 그 컨테이너에 대해서 다시 지연시간을 초기화 시킨다.
자료 출처
https://bikramat.medium.com/pod-lifecycle-5ed682d0ae8d
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
Pod Lifecycle
This page describes the lifecycle of a Pod. Pods follow a defined lifecycle, starting in the Pending phase, moving through Running if at least one of its primary containers starts OK, and then through either the Succeeded or Failed phases depending on whet
kubernetes.io
'Cloud Engineering > Kubernetes ⚙️' 카테고리의 다른 글
| [Kubernetes] Replication Controller (레플리케이션 컨트롤러) (0) | 2023.02.11 |
|---|---|
| [Kubernetes] 컨테이너 프로브 (Container Probe) (0) | 2023.02.11 |
| [Kubernetes] Namespace 생성, 삭제, 확인하기 (0) | 2023.02.09 |
| [Kubernetes] Annotation 추가하기 (0) | 2023.02.09 |
| [Kubernetes] Pod 생성 및 삭제하기 (0) | 2023.02.09 |