
728x90
Paging 기법과 주소 변환
- Paging 기법에서는 프로그램을 구성하는 주소 공간이 동일한 크기의 Page 라는 단위로 잘려서, 각각의 Page가 물리적 메모리의 어디에나 올라갈 수 있다.
- 각각의 Page들이 어느 위치에 올라가 있는지 알기 위해서는 Page별로 주소 변환이 필요하다.
Paging 기법
- 물리 메모리는 Frame 이라 불리는 같은 크기의 블록으로 나누어진다.
- 논리메모리는 Page라 불리는 같은 크기의 블록으로 나누어진다.
- Page Table에서 논리적인 주소에서 물리적인 주소로 주소 변환을 한다. 따라서 Page Table에서는 logical memory 의 개수만큼 entry 가 존재하게 된다.
- Index를 이용해서 곧바로 접근할 수 있는 자료 구조 형태이다.
- 각각의 Page는 Code, Data, Stack 으로 구성된다.
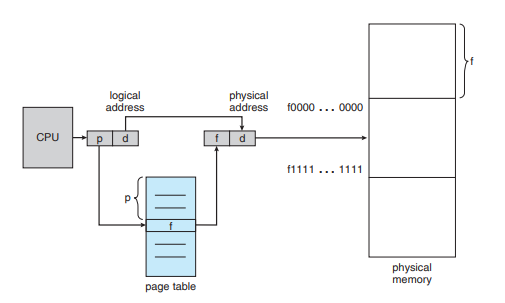

- 페이징 기법에서는 주소 변환에 Page Table을 사용하게 된다.
- p 는 페이지 번호가 되고 d는 페이지 내에서 얼마나 떨어져 있는지를 나타내는 offset이 될 것이다.
- f 는 Frame 번호 (물리적 메모리) 로, page table에서 찾아서 매핑해주고 있다.
메모리 주소 공간 체계 32bit, 64bit
32bit 주소 공간에서는 최대로 주소 공간을 구별할 수 있는 개수가 2^32 개 이다.
페이지 테이블 구현
- Page Table은 메인 메모리에 상주
- Page-Table Base Register 는 Page Table이 어디서부터 시작하는지, Page Table의 시작 위치를 가리킨다.
- Page-Table Length Register 가 테이블 크기를 보관한다.
- 모든 메모리 접근 연산에는 2번의 memory access가 필요
- Page Table 접근 1번, 실제 data/instruction 접근 1번
페이지 테이블과 TLB (Translation Look-Aside Buffer)

- 속도 향상을 위해 associative register, 혹은 TLB (translation look-aside buffer) 를 사용한다.
- TLB도 일종의 캐시메모리로, 주소 변환을 빠르게 하기 위한 용도이다. TLB는 캐시라는 특성상 페이지 테이블의 일부 정보를 담고 있게 된다.
- 우선적으로 logical address를 통해 TLB 에 먼저 접근하여 정보를 확인하지만 정보가 없는 경우, 이를 TLB miss 라고 한다. 이 경우에는 page table을 통해서 주소 변환이 필요하다.
- TLB는 페이지 테이블 정보의 일부분만을 담고 있기 때문에, page number + frame number 쌍으로 정보를 들고 있어야 한다.
- p 라는 페이지에 대한 주소 정보가 TLB에 있는지 없는지 전부 스캔이 필요하다. 따라서 오버헤드가 크다. -> 이를 해결하기 위해서 병렬적으로 정보를 찾는 방법이 효율적이며, 이 역할을 해주는 하드웨어가 associative register 이다.
Associative Registers (TLB)
- parallel search 가 가능하다.
- 주소 변환의 경우, page table 중 일부가 associative register에 보관되어 있다.
- 해당 page #가 associate register에 있는 경우 곧바로 frame # 를 얻는다.
- 그렇지 않은 경우 (TLB miss) main memory 에 있는 page table 로 부터 frame # 를 얻는다.
- TLB 는 context switching 이 일어날 때 전부 플러시 되어야 한다. 각 프로세스마다 논리적인 주소가 다르기 때문이다. 그리고 context switching의 주요 오버헤드의 원인 중 하나가 이 TLB 플러시이다. (remove old entries)
Two-Level Page Table (2단계 페이지 테이블)
현대의 컴퓨터는 address space 가 매우 큰 프로그램 지원
- ex. 32bit address 사용시 2**32 의 주소 공간 사용.
- page size가 4K 일때 1M개의 page table entry 가 필요하다.
- 각 page entry 가 4B 프로세스당 4M의 page table 필요
- 그러나 대부분의 프로그램은 4G의 주소 공간 중 지극히 일부분만 사용하므로 page table 공간이 심하게 낭비됨
- page table 자체를 page로 구성하는 방법
- 사용되지 않는 주소 공간에 대한 outer page table의 entry 값은 NULL 이다. (대응하는 inner page table이 없음!)
- 주소변환을 위해서 메모리에 2번 접근, 실제 데이터 접근을 위한 메모리 접근 1번 이므로 시간상으로 손해이지만 공간상으로 이득을 볼 수 있다.
다단계 페이지 테이블
- Address Space가 더 커지게 되면 다단계 페이지 테이블이 필요할 것이다.
- 공간은 효율적으로 사용할 수 있으나, 주소 변환을 위해 메모리에 접근하는 과정이 늘어나므로 시간 복잡도가 늘어나게 된다.
Memory Protection
Page Table의 각 entry 마다 아래의 bit를 둔다
- Protection bit : page 에 대한 접근 권한 (read/write/read-only)
- Valid-Invalid Bit
- valid : 해당 주소의 frame에 그 프로세스를 구성하는 유효한 내용이 있음을 뜻함 (접근 허용)
- invalid : 해당 주소의 frame 에 유효한 내용이 없음을 뜻함 (접근 불허). 프로세스가 주소 부분을 사용하지 않거나, 해당 페이지가 메모리에 올라와 있지 않고 swap area에 있는 경우이다.
- 각각의 프로세스들 마다 page table 들이 존재하게 된다. 주소 변환을 하더라도 자기 자신의 프로세스에 대해서만 접근을 할 수 있다.
- 어처피 접근 권한은 해당 프로세스에 대한 권한만 가지고 있으나, Protection bit가 r/w/ro에 대한 권한을 표시할 수 있다.
역 페이지 테이블
- 기존 페이지 테이블 기법의 단점은 각 페이지 테이블 항목의 개수가 수백만 개가 될 수 있다는 점으로, 많은 양의 물리 메모리를 소비하게 된다. (공간 복잡도 증가!)
- 물리적인 메모리 프레임마다 한 항목을 할당한다. 각 항목은 그 프레임에 올라와 있는 페이지 주소+ 페이지를 소유하고 있는 프로세스의 PID 를 표시한다.
- 시스템에는 단 하나의 페이지 테이블만 존재하게 되고 테이블 내 각 항목은 메모리의 한 프레임을 가리킨다.
- 장점 : 논리페이지마다 항목을 가지는 대신, 물리 프레임에 대응되는 항목만 페이지 테이블에 저장하므로 메모리 크기를 적게 차지한다.
- 단점 : 역 페이지 테이블은 물리 주소에 따라 정렬되어 있고, 탐색은 가상 주소를 기준으로 하므로 테이블 전체를 탐색해야 한다.
Shared Page
페이징의 장점은 공통의 코드를 공유할 수 있다는 점이다.
- Shared Code - 코드를 공유하기 위한 제약 조건
- Re-entrant Code (= Pure Code)
- read-only 로 하여 프로세스 간에 하나의 code 만 메모리에 올림 ex. compilers, text editors..
- shared code는 모든 프로세스의 logical address space에서 동일한 위치에 있어야 함
- Private Code and Data
- 각 프로세스들은 독자적으로 메모리에 올림
- private data는 logical address space의 아무 곳에 와도 무방함.
728x90
'Computer Science > 운영체제' 카테고리의 다른 글
| [운영체제] 20. Memory Management (3) - Segment (0) | 2023.11.26 |
|---|---|
| [운영체제] 18.Memory Management (1) (0) | 2023.11.05 |
| [운영체제] 교착상태 (0) | 2023.08.08 |
| [운영체제] 14. 세마포어와 동기화 문제와 해결 (Bounded-Buffer, Readers-Writers Problem, 식사하는 철학자 문제) (0) | 2023.07.30 |
| [운영체제] 12. 임계구역(Critical Section) 문제 & 세마포어 (Semaphore) & 뮤텍스 (Mutex) (0) | 2023.07.23 |