
검색 엔진으로 알려져 있는 OpenSearch (ElasticSearch) 를 RAG로 활용한 경험에 대해 소개해보려고 한다.
OpenSearch 란 무엇인가 ? ElasticSearch 와 무슨 차이지?
OpenSearch 는 ElasticSearch 라는 오픈소스 제품을 AWS가 Fork 해서 개발한 제품이다. 그리고 AWS가 ElasticSearch 를 제품화 해서 서비스로 제공하는 검색 엔진 서비스가 OpenSearch 이다. 원래 오픈소스를 복사하는 일 자체는 종종 일어나지만, 오픈소스를 제품화 해서 다른 업계에 타격을 주었기 때문에 논란이 되고 있다. 2023년 기준으로 오픈서치의 다운로드 건수는 1억을 넘겼으니, 결국 AWS가 성공한 셈이다. 필자는 AWS 서비스를 사용하고 있었으며, AWS 클라우드 인프라 내부에서 RAG를 구축해야 했으므로 OpenSearch 를 사용하게 되었다.
챗봇에서 RAG는 어떤 역할일까?
기존에 NLP 나 LLM 관련해서 작업을 하고 있었다면 익숙하겠지만, 필자는 챗봇 프로젝트를 하게 되면서 처음으로 RAG라는 개념을 접하게 되었다. RAG 는 Retrieval-Augmented Generation 의 약자로, 문서 검색기와 LLM 을 통합하는 아키텍처라고 할 수 있다. 챗봇에 사용자가 질의를 입력하면, 해당 질의에 기반하여 대량의 문서에서 관련 정보를 검색한다. 그리고 검색한 정보를 바탕으로 LLM 이 자연어 텍스트를 생성한다. 이 RAG 아키텍처에서 OpenSearch는 문서 검색의 역할을 위해 사용하게 되었다.
RAG의 장점으로는 LLM의 환각 현상 (Hallucination) 감소에 도움이 된다는 점이 있다. LLM 은 생성형 AI라는 특징상, 100% 정답만을 생성하지는 않을 것이며 오답이라도 일단 생성해내게 된다. RAG는 외부 데이터베이스에서 데이터를 가져와서 오답을 생성하는 환각 현상을 줄이는데 도움이 된다. 또한 앞서 말한 것과 같이 특정 도메인의 정보를 외부 데이터베이스에 담고, 이를 검색하여 LLM 과 연계해서 답변을 주게 된다면 특정 도메인에 대한 챗봇을 개발할 수 있을 것이다.
Vector Database와 RAG의 구성
RAG 아키텍처에서 '외부 데이터베이스'로 Vector Database가 많이 활용되고 있다. Vector Database는 말 그대로 'Vector' 값을 저장하는 데이터베이스이다. 고차원 벡터를 데이터베이스 공간에 저장하여 N차원 공간에서 가장 가까운 이웃을 효율적이고 빠르게 검색할 수 있다는 특징이 있다. RDBMS 같은 전형적인 데이터베이스가 아닌 Vector DB를 사용하게 된 맥락에는, 데이터를 'Embedding' 해야하는 이유에서 찾을 수 있다.

Embedding 이란 ?
Embedding이란 단어를 Dense Vector로 표현하는 방법이다. (Dense Vector가 무엇인지는 뒤에서 설명) NLP에서 사람이 쓰는 자연어를 기계가 이해할 수 있도록 숫자 형태로 변환하는 과정을 의미한다.
Embedding의 장점은 다음과 같다.
우선, 데이터가 너무 큰 용량을 차지하는 경우, raw data를 바로 저장하는 것은 효율적이지 않으며 의미론적인 정보를 포함하기 어렵다. 따라서 유사한 text가 유사한 숫자값을 갖게 되는 embedding에서는 의미적인 정보를 포함할 수 있다.
두번째로, Embedding을 통해서 글이나 이미지, 동영상 같은 비정형 데이터를 숫자 (Vector)값으로 표현할 수 있다.
Embedding의 주요 기법 3가지는 다음과 같다.
먼저, One-Hot 인코딩 방식이다. 문장에서 단어를 1 로 표현하는 인코당 방식이다.

그렇지만 이 방법은 대부분의 값들이 0이어서 너무 sparse 하며, 한 문장을 표현하는데 너무 큰 공간이 필요하다는 단점이 있다.
두번째로, 단어를 고유 번호로 인코딩하는 방식이다. 첫번째 방식에서는 단어를 무조건 1로 나타냈다면, 이 방법은 고유 번호를 사용하여 [5,1,4,3,5,2] 와 같이 인코딩할 수 있다.
그러나 단어 간의 유사도를 표현하기가 어렵다는 단점이 있다.
마지막으로 Word Embedding 방식이다. 유사한 단어의 경우 유사한 인코딩 값을 갖는 Dense Vector 표현으로 인코딩하는 방식이다.

Dense Vector 란 벡터의 차원을 단어 집합이 가지고 있는 크기로 동일하게 지정하는 것이 아니라, 단어 집합의 크기와 상관없이 사용자가 사전에 설정한 동일한 차원 값으로 모든 단어 집합을 벡터값으로 표현하는 것이다. 예를 들어서, OpenAI사의 text-embedding-ada-002 라는 Embedding Model 은 어떤 길이의 문장을 넣더라도 1536 차원을 가지는 벡터값으로 임베딩된다.
OpenSearch를 RAG로 사용해보자
검색 엔진용이나 실시간 로그를 저장 및 분석하는 용도로 많은 회사에서 이미 ElasticSearch 혹은 OpenSearch 를 도입해서 사용하고 있다. LLM과 Chatbot이라는 시대의 트렌드에 맞게 OpenSearch에서 k-NN 검색을 지원하는 기능이 등장했다.

여기서 k-NN 알고리즘이란 k-Nearest Neighbor의 줄임말이다. 새로운 데이터가 들어오면 데이터 베이스에 저장되어 있는 데이터들과 비교하여 가장 거리가 가까운 k 의 데이터로 예측 또는 분류를 수행 하는 알고리즘이다. 거리를 계산할 때는 유클리드 거리 또는 코사인 유사도를 사용하여 계산할 수 있다.
k-NN 알고리즘의 작동 방식
1. 새로운 데이터가 공간에 입력되었을 때 기존에 저장되어 있는 데이터와 새로 들어온 데이터를 비교한다.
2. 새로운 데이터와 가장 인접한 데이터 k 개를 선정한다.
3. k 값에 의해 결정된 분류를 입력된 데이터의 그룹으로 분류한다.
단, 여기서 최적의 k 값을 결정하기 위한 이론적 모델은 존재하지 않으며 실험적으로 결정할 수 있다.
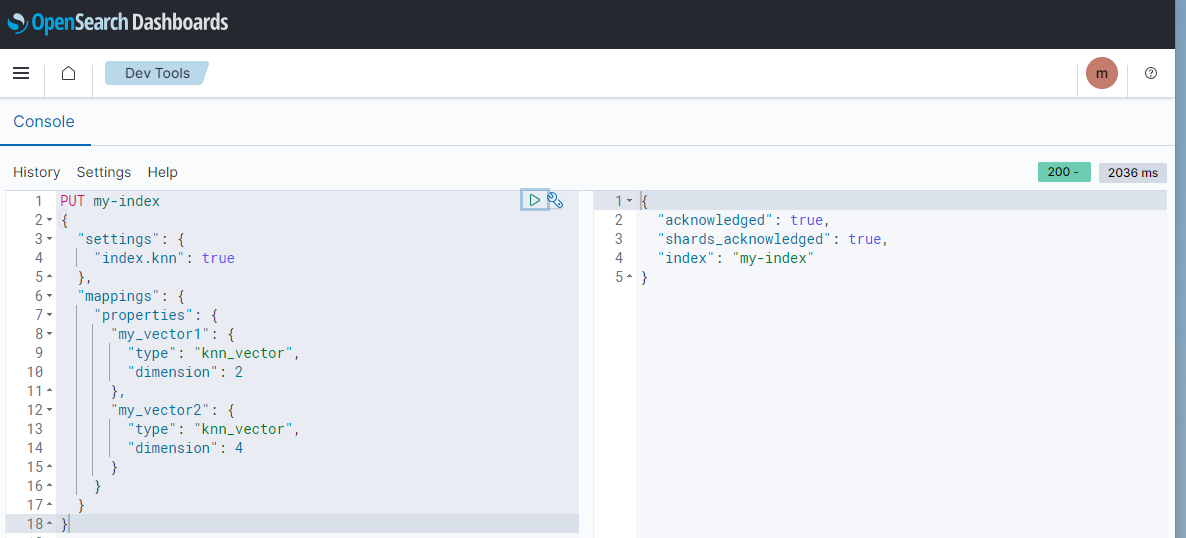
OpenSearch에서 k-NN 검색을 사용하기 위해서는 Index를 생성할 때 부터 index.knn 값을 반드시 true로 설정해 주어야 한다. 그리고 "knn_vector" 라는 field type과 해당 vector field 가 가지는 차원의 값을 설정해주어야 한다.
PUT my-index
{
"settings": {
"index.knn": true
},
"mappings": {
"properties": {
"my_vector1": {
"type": "knn_vector",
"dimension": 2
},
"my_vector2": {
"type": "knn_vector",
"dimension": 4
}
}
}
}주의할 점은, 나중에 사용자 질문을 vector embedding 값으로 바꾸어서 검색할때의 vector dimension 과 OpenSearch Index에 저장되는 knn_vector field 의 dimension 이 일치해야 한다는 것이다.

위에서 생성한 Index에 데이터를 Indexing 할 수 있다.


Vector 값으로 근접한 이웃수 2개 (k 값을 2로 설정)를 조회하는 쿼리이다.
다음과 같이, [2, 3] 이라는 벡터 값과 가장 유사한 벡터값을 갖는 결과값 2개를 얻을 수 있다.
위에서 kNN 검색을 적용한 예시를 살펴보았다. 이를 문서와 함께 적용하고 싶다면 field를 다음과 같이 구성할 수 있을 것이다.
| Field 명 (예시) | Field 설명 | Field Type |
| vector_field | 문서를 임베딩 한 값 | knn_vector |
| text | 문서 내용 | text |
| title | 문서의 제목 (메타데이터) | text |
"vector_field" 에는 text를 embedding 한 값을 저장한다. 그리고 사용자가 OpenSearch 에 질의를 날릴 때, 해당 질의를 vector로 embedding 한 값과 미리 인덱싱 되어 있는 vector_field 의 embedding 값과 비교하여 가장 근접한 k 개의 문서를 검색할 수 있다.
이때 OpenSearch 로 요청하는 query 의 예시는 다음과 같다.
GET my-index/_search
{
"size" : 2,
"query" : {
"knn" : {
"vector_field" : {
"vector" : [사용자 질문을 EMBEDDING한 값],
"k" : 2
}
}
}
}OpenSearch RAG를 Chatbot에 적용한 간단한 아키텍처
AWS 의 공식 블로그에서 제안하고 있는 OpenSearch 기반의 Chatbot 아키텍처를 소개하며 글을 마치겠다.

위의 챗봇 아키텍처는 빠르게 구현해 볼 수 있는 가장 간단한 아키텍처 중 하나라고 생각했다. Streamlit 라이브러리를 Chatbot Web Application UI를 개발할 때 사용하여 빠르게 개발할 수 있으며, 이를 Lambda+API Gateway 로 배포하고 있다. OpenSearch 서비스를 VectorDB로 활용하여 사용자 질문과 가장 유사한 문서를 검색해온 다음, 사용자 질문과 문서를 LLM 의 Prompt로 던진다. LLM 이 답변을 생성하게 되면 이를 다시 Lambda를 거쳐 Streamlit Web Application으로 사용자에게 보여준다.
저기서 아키텍처를 더 확장해 본다면, 사용자의 챗봇 사용 기록 및 피드백을 수집하여 챗봇 품질을 개선하는 (RLHF - Reinforcement Human Feedback) 도 시도해 볼 수 있을 것이다. 또한 RAG를 구성하는 문서가 S3에 새롭게 들어왔을 대 이벤트를 감지하여 자동으로 인덱싱하는 자동화 파이프라인도 구축해볼 수 있을 것이다.
참고로 Lambda와 API Gateway 를 이용하여 API 를 배포하는 방법의 포스팅은 아래를 참고하시면 될 것 같다.
https://sinclairstudio.tistory.com/587
[AWS] Lambda 와 API Gateway 로 서버리스 API 구축하기 - GET 요청에서 parameter 보내기
Lambda 함수를 trigger 거는 방법에는 여러가지가 있지만 그중에서도 AWS 외부에서 lambda 에 요청을 보내기 위해서 API Gateway 와 연동하게 되면, lambda 함수를 빠르게 서버리스로 배포할 수 있다. API Gatew
sinclairstudio.tistory.com
글을 마치며 ...
AWS SA 들의 강의 세션을 종종 들을 일이 있는데, AWS에서는 LLM 기반 챗봇을 구성할 때 있어서 OpenSearch 라는 서비스를 추천.. (밀고있는?) 한다는 느낌을 받았다. 사실 RAG를 구성하기 위해서는 반드시 OpenSearch 를 사용할 필요는 없다. 더 hot 한 Vector DB인 Chroma DB, pinecone이 이미 시장에서는 널리 알려져 있으며 경량 VectorIndex에 해당하는 LlmaIndex와 같은 오픈소스도 나와있다. 한편 AWS의 지능형 검색 서비스인 Kendra 라는 제품도 있는데, 이 제품을 사용하면 문서 source data 만 연결해주면 알아서 임베딩까지 내부적으로 해주는 것 같다. (어떻게 동작하는 지는 AWS가 외부에 공개하지 않고 있는 듯 하다.)
결론은, 본인이 RAG를 구축하려는 환경의 특성을 고려하여 제품을 선택하면 될 것이다. OpenSearch(ElasticSearch) 를 선택하는 경우에는 이미 클러스터가 구축되어 있는 경우에 Index만 새로 생성해주면 되기 때문에 개발을 빠르게 할 수 있을 것이라고 생각했다. OpenSearch는 Kibana Dashboard도 제공하니까 빠르게 API 와 통신하거나 SQL query로 간단히 문서 내용을 확인하는 작업이 가능해서 편리했다. 또한 임베딩 값 유사도 비교 뿐만 아니라 기존의 OpenSearch 의 강력한 검색 기능도 쿼리에 결합해서 검색 성능을 높일 수 있을 것이다.
Reference
- https://aws.amazon.com/ko/what-is/vector-databases/
- https://hackernoon.imgix.net/images/yhEhPLascChMpCTtzmkf1sRv2sM2-o893ui5.jpeg
- https://docs.aws.amazon.com/ko_kr/opensearch-service/latest/developerguide/knn.html
- https://aws.amazon.com/ko/blogs/machine-learning/build-a-powerful-question-answering-bot-with-amazon-sagemaker-amazon-opensearch-service-streamlit-and-langchain/
'Data Engineering' 카테고리의 다른 글
| [TIL/240520] Data Engineering on Databricks (1) | 2024.05.20 |
|---|---|
| 데이터 인프라 이해하기, Spark + HDFS + Hive (0) | 2024.02.17 |
| [Apache Airflow] Airflow 설치하기 (0) | 2023.10.22 |
| [Colab] 코랩 런타임 연결 끊김 방지하기 (0) | 2023.07.23 |
| 빅데이터로 성공하기 (서가명강 조성준 교수님 강의) 요약 (0) | 2023.04.02 |
검색 엔진으로 알려져 있는 OpenSearch (ElasticSearch) 를 RAG로 활용한 경험에 대해 소개해보려고 한다.
OpenSearch 란 무엇인가 ? ElasticSearch 와 무슨 차이지?
OpenSearch 는 ElasticSearch 라는 오픈소스 제품을 AWS가 Fork 해서 개발한 제품이다. 그리고 AWS가 ElasticSearch 를 제품화 해서 서비스로 제공하는 검색 엔진 서비스가 OpenSearch 이다. 원래 오픈소스를 복사하는 일 자체는 종종 일어나지만, 오픈소스를 제품화 해서 다른 업계에 타격을 주었기 때문에 논란이 되고 있다. 2023년 기준으로 오픈서치의 다운로드 건수는 1억을 넘겼으니, 결국 AWS가 성공한 셈이다. 필자는 AWS 서비스를 사용하고 있었으며, AWS 클라우드 인프라 내부에서 RAG를 구축해야 했으므로 OpenSearch 를 사용하게 되었다.
챗봇에서 RAG는 어떤 역할일까?
기존에 NLP 나 LLM 관련해서 작업을 하고 있었다면 익숙하겠지만, 필자는 챗봇 프로젝트를 하게 되면서 처음으로 RAG라는 개념을 접하게 되었다. RAG 는 Retrieval-Augmented Generation 의 약자로, 문서 검색기와 LLM 을 통합하는 아키텍처라고 할 수 있다. 챗봇에 사용자가 질의를 입력하면, 해당 질의에 기반하여 대량의 문서에서 관련 정보를 검색한다. 그리고 검색한 정보를 바탕으로 LLM 이 자연어 텍스트를 생성한다. 이 RAG 아키텍처에서 OpenSearch는 문서 검색의 역할을 위해 사용하게 되었다.
RAG의 장점으로는 LLM의 환각 현상 (Hallucination) 감소에 도움이 된다는 점이 있다. LLM 은 생성형 AI라는 특징상, 100% 정답만을 생성하지는 않을 것이며 오답이라도 일단 생성해내게 된다. RAG는 외부 데이터베이스에서 데이터를 가져와서 오답을 생성하는 환각 현상을 줄이는데 도움이 된다. 또한 앞서 말한 것과 같이 특정 도메인의 정보를 외부 데이터베이스에 담고, 이를 검색하여 LLM 과 연계해서 답변을 주게 된다면 특정 도메인에 대한 챗봇을 개발할 수 있을 것이다.
Vector Database와 RAG의 구성
RAG 아키텍처에서 '외부 데이터베이스'로 Vector Database가 많이 활용되고 있다. Vector Database는 말 그대로 'Vector' 값을 저장하는 데이터베이스이다. 고차원 벡터를 데이터베이스 공간에 저장하여 N차원 공간에서 가장 가까운 이웃을 효율적이고 빠르게 검색할 수 있다는 특징이 있다. RDBMS 같은 전형적인 데이터베이스가 아닌 Vector DB를 사용하게 된 맥락에는, 데이터를 'Embedding' 해야하는 이유에서 찾을 수 있다.
Embedding 이란 ?
Embedding이란 단어를 Dense Vector로 표현하는 방법이다. (Dense Vector가 무엇인지는 뒤에서 설명) NLP에서 사람이 쓰는 자연어를 기계가 이해할 수 있도록 숫자 형태로 변환하는 과정을 의미한다.
Embedding의 장점은 다음과 같다.
우선, 데이터가 너무 큰 용량을 차지하는 경우, raw data를 바로 저장하는 것은 효율적이지 않으며 의미론적인 정보를 포함하기 어렵다. 따라서 유사한 text가 유사한 숫자값을 갖게 되는 embedding에서는 의미적인 정보를 포함할 수 있다.
두번째로, Embedding을 통해서 글이나 이미지, 동영상 같은 비정형 데이터를 숫자 (Vector)값으로 표현할 수 있다.
Embedding의 주요 기법 3가지는 다음과 같다.
먼저, One-Hot 인코딩 방식이다. 문장에서 단어를 1 로 표현하는 인코당 방식이다.
그렇지만 이 방법은 대부분의 값들이 0이어서 너무 sparse 하며, 한 문장을 표현하는데 너무 큰 공간이 필요하다는 단점이 있다.
두번째로, 단어를 고유 번호로 인코딩하는 방식이다. 첫번째 방식에서는 단어를 무조건 1로 나타냈다면, 이 방법은 고유 번호를 사용하여 [5,1,4,3,5,2] 와 같이 인코딩할 수 있다.
그러나 단어 간의 유사도를 표현하기가 어렵다는 단점이 있다.
마지막으로 Word Embedding 방식이다. 유사한 단어의 경우 유사한 인코딩 값을 갖는 Dense Vector 표현으로 인코딩하는 방식이다.
Dense Vector 란 벡터의 차원을 단어 집합이 가지고 있는 크기로 동일하게 지정하는 것이 아니라, 단어 집합의 크기와 상관없이 사용자가 사전에 설정한 동일한 차원 값으로 모든 단어 집합을 벡터값으로 표현하는 것이다. 예를 들어서, OpenAI사의 text-embedding-ada-002 라는 Embedding Model 은 어떤 길이의 문장을 넣더라도 1536 차원을 가지는 벡터값으로 임베딩된다.
OpenSearch를 RAG로 사용해보자
검색 엔진용이나 실시간 로그를 저장 및 분석하는 용도로 많은 회사에서 이미 ElasticSearch 혹은 OpenSearch 를 도입해서 사용하고 있다. LLM과 Chatbot이라는 시대의 트렌드에 맞게 OpenSearch에서 k-NN 검색을 지원하는 기능이 등장했다.
여기서 k-NN 알고리즘이란 k-Nearest Neighbor의 줄임말이다. 새로운 데이터가 들어오면 데이터 베이스에 저장되어 있는 데이터들과 비교하여 가장 거리가 가까운 k 의 데이터로 예측 또는 분류를 수행 하는 알고리즘이다. 거리를 계산할 때는 유클리드 거리 또는 코사인 유사도를 사용하여 계산할 수 있다.
k-NN 알고리즘의 작동 방식
1. 새로운 데이터가 공간에 입력되었을 때 기존에 저장되어 있는 데이터와 새로 들어온 데이터를 비교한다.
2. 새로운 데이터와 가장 인접한 데이터 k 개를 선정한다.
3. k 값에 의해 결정된 분류를 입력된 데이터의 그룹으로 분류한다.
단, 여기서 최적의 k 값을 결정하기 위한 이론적 모델은 존재하지 않으며 실험적으로 결정할 수 있다.
OpenSearch에서 k-NN 검색을 사용하기 위해서는 Index를 생성할 때 부터 index.knn 값을 반드시 true로 설정해 주어야 한다. 그리고 "knn_vector" 라는 field type과 해당 vector field 가 가지는 차원의 값을 설정해주어야 한다.
PUT my-index
{
"settings": {
"index.knn": true
},
"mappings": {
"properties": {
"my_vector1": {
"type": "knn_vector",
"dimension": 2
},
"my_vector2": {
"type": "knn_vector",
"dimension": 4
}
}
}
}주의할 점은, 나중에 사용자 질문을 vector embedding 값으로 바꾸어서 검색할때의 vector dimension 과 OpenSearch Index에 저장되는 knn_vector field 의 dimension 이 일치해야 한다는 것이다.
위에서 생성한 Index에 데이터를 Indexing 할 수 있다.
Vector 값으로 근접한 이웃수 2개 (k 값을 2로 설정)를 조회하는 쿼리이다.
다음과 같이, [2, 3] 이라는 벡터 값과 가장 유사한 벡터값을 갖는 결과값 2개를 얻을 수 있다.
위에서 kNN 검색을 적용한 예시를 살펴보았다. 이를 문서와 함께 적용하고 싶다면 field를 다음과 같이 구성할 수 있을 것이다.
| Field 명 (예시) | Field 설명 | Field Type |
| vector_field | 문서를 임베딩 한 값 | knn_vector |
| text | 문서 내용 | text |
| title | 문서의 제목 (메타데이터) | text |
"vector_field" 에는 text를 embedding 한 값을 저장한다. 그리고 사용자가 OpenSearch 에 질의를 날릴 때, 해당 질의를 vector로 embedding 한 값과 미리 인덱싱 되어 있는 vector_field 의 embedding 값과 비교하여 가장 근접한 k 개의 문서를 검색할 수 있다.
이때 OpenSearch 로 요청하는 query 의 예시는 다음과 같다.
GET my-index/_search
{
"size" : 2,
"query" : {
"knn" : {
"vector_field" : {
"vector" : [사용자 질문을 EMBEDDING한 값],
"k" : 2
}
}
}
}OpenSearch RAG를 Chatbot에 적용한 간단한 아키텍처
AWS 의 공식 블로그에서 제안하고 있는 OpenSearch 기반의 Chatbot 아키텍처를 소개하며 글을 마치겠다.
위의 챗봇 아키텍처는 빠르게 구현해 볼 수 있는 가장 간단한 아키텍처 중 하나라고 생각했다. Streamlit 라이브러리를 Chatbot Web Application UI를 개발할 때 사용하여 빠르게 개발할 수 있으며, 이를 Lambda+API Gateway 로 배포하고 있다. OpenSearch 서비스를 VectorDB로 활용하여 사용자 질문과 가장 유사한 문서를 검색해온 다음, 사용자 질문과 문서를 LLM 의 Prompt로 던진다. LLM 이 답변을 생성하게 되면 이를 다시 Lambda를 거쳐 Streamlit Web Application으로 사용자에게 보여준다.
저기서 아키텍처를 더 확장해 본다면, 사용자의 챗봇 사용 기록 및 피드백을 수집하여 챗봇 품질을 개선하는 (RLHF - Reinforcement Human Feedback) 도 시도해 볼 수 있을 것이다. 또한 RAG를 구성하는 문서가 S3에 새롭게 들어왔을 대 이벤트를 감지하여 자동으로 인덱싱하는 자동화 파이프라인도 구축해볼 수 있을 것이다.
참고로 Lambda와 API Gateway 를 이용하여 API 를 배포하는 방법의 포스팅은 아래를 참고하시면 될 것 같다.
https://sinclairstudio.tistory.com/587
[AWS] Lambda 와 API Gateway 로 서버리스 API 구축하기 - GET 요청에서 parameter 보내기
Lambda 함수를 trigger 거는 방법에는 여러가지가 있지만 그중에서도 AWS 외부에서 lambda 에 요청을 보내기 위해서 API Gateway 와 연동하게 되면, lambda 함수를 빠르게 서버리스로 배포할 수 있다. API Gatew
sinclairstudio.tistory.com
글을 마치며 ...
AWS SA 들의 강의 세션을 종종 들을 일이 있는데, AWS에서는 LLM 기반 챗봇을 구성할 때 있어서 OpenSearch 라는 서비스를 추천.. (밀고있는?) 한다는 느낌을 받았다. 사실 RAG를 구성하기 위해서는 반드시 OpenSearch 를 사용할 필요는 없다. 더 hot 한 Vector DB인 Chroma DB, pinecone이 이미 시장에서는 널리 알려져 있으며 경량 VectorIndex에 해당하는 LlmaIndex와 같은 오픈소스도 나와있다. 한편 AWS의 지능형 검색 서비스인 Kendra 라는 제품도 있는데, 이 제품을 사용하면 문서 source data 만 연결해주면 알아서 임베딩까지 내부적으로 해주는 것 같다. (어떻게 동작하는 지는 AWS가 외부에 공개하지 않고 있는 듯 하다.)
결론은, 본인이 RAG를 구축하려는 환경의 특성을 고려하여 제품을 선택하면 될 것이다. OpenSearch(ElasticSearch) 를 선택하는 경우에는 이미 클러스터가 구축되어 있는 경우에 Index만 새로 생성해주면 되기 때문에 개발을 빠르게 할 수 있을 것이라고 생각했다. OpenSearch는 Kibana Dashboard도 제공하니까 빠르게 API 와 통신하거나 SQL query로 간단히 문서 내용을 확인하는 작업이 가능해서 편리했다. 또한 임베딩 값 유사도 비교 뿐만 아니라 기존의 OpenSearch 의 강력한 검색 기능도 쿼리에 결합해서 검색 성능을 높일 수 있을 것이다.
Reference
- https://aws.amazon.com/ko/what-is/vector-databases/
- https://hackernoon.imgix.net/images/yhEhPLascChMpCTtzmkf1sRv2sM2-o893ui5.jpeg
- https://docs.aws.amazon.com/ko_kr/opensearch-service/latest/developerguide/knn.html
- https://aws.amazon.com/ko/blogs/machine-learning/build-a-powerful-question-answering-bot-with-amazon-sagemaker-amazon-opensearch-service-streamlit-and-langchain/
'Data Engineering' 카테고리의 다른 글
| [TIL/240520] Data Engineering on Databricks (1) | 2024.05.20 |
|---|---|
| 데이터 인프라 이해하기, Spark + HDFS + Hive (0) | 2024.02.17 |
| [Apache Airflow] Airflow 설치하기 (0) | 2023.10.22 |
| [Colab] 코랩 런타임 연결 끊김 방지하기 (0) | 2023.07.23 |
| 빅데이터로 성공하기 (서가명강 조성준 교수님 강의) 요약 (0) | 2023.04.02 |