

Python 의 GIL (Global Interpreter Lock)
Python은 멀티 스레딩 환경에서 두 개이상의 스레드가 동시에 동일한 자원에 접근하는 것을 방지하기 위해 GIL 매커니즘을 사용한다. GIL에 의해 CPU bound 작업을 처리하는 경우 한번에 하나의 스레드만 실행하도록 동작한다. 반면 I/O bound 작업의 경우에는 I/O 작업 중에 GIL가 해제되기 때문에 GIL의 영향이 상대적으로 적다. 이렇게 하나의 스레드만 사용하게 되는 GIL의 제약사항을 극복하기 위해서 Python에서 threading 과 multiprocessing 을 사용했다. 각 Python 의 프로세스가 자체적인 메모리 공간과 GIL 를 가지므로 여러 CPU 코어를 사용한 병렬처리가 가능하다. 그리고 Python3.2 부터 Concurrent.future 모듈이 등장했다.
Concurrent.future 모듈
Concurrent.futures 모듈은 Python에서 비동기 처리를 할 수 있도록 고수준의 인터페이스를 제공하는 모듈이다. Concurrent.future에는 ThreadPoolExecutor와 ProcessPoolExecutor 라는 두가지 주요한 실행자 클래스가있다. 이 실행자(Executor)는 작업의 실행을 관리하는 객체를 의미한다. 즉, 프로세스 및 스레드 객체를 직접적으로 작성하지 않고도 함수 호출을 객체화 하여 병렬 작업을 실행할 수 있다.
주요 특징
1. Executor
- ThreadPoolExecutor : thread 기반의 병렬실행을 위한 클래스이다. I/O-bound 작업을 병렬로 수행할 때 유용하다.
- ProcessPoolExecutor : Process 기반의 병렬 실행을 위한 클래스이다. CPU-bound 작업을 병렬로 수행할 때 유용하다.
2. Future 객체
Future 객체는 비동기 실행의 결과를 나타낸다. 실행중이거나 완료된 작업에 대한 상태와 결과를 캡슐화한다.
3. 작업 제출 및 결과 처리
- Executor.submit() : 실행할 함수와 파라미터를 실행자(executor)에게 제출(submit)하면 Future 객체가 반환된다.
- Future.result() : 작업의 결과를 Future 객체로부터 얻을 수 있다.
ThreadPool 이란
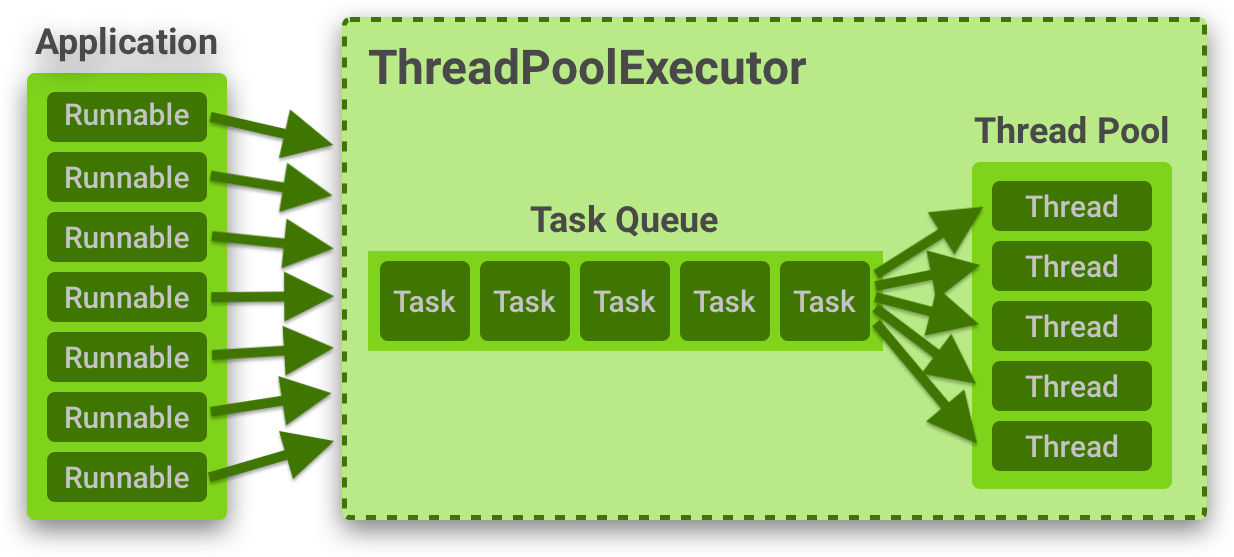
병렬처리 작업이 많아지게 되면 thread수가 증가하고 새로운 thread 생성과 스케줄링 작업으로 인해 메모리 사용량이 증가한다. 갑자기 병렬작업이 증가하여 시스템 성능이 저하되는 것을 방지하기 위해 Thread Pool 을 사용할 수 있다. ThreadPool은 작업처리에 사용되는 thread를 제한된 개수(ThreadPoolExecutor에서는 max_workers 에 해당한다.)만큼 정하여 pool 에 둔다. 그리고 task queue에 들어와서 대기중인 task 를 thread가 하나씩 처리하게한다. 이렇게 했을 때의 이점은 갑자기 작업이 증가하더라도 thread 의 전체 개수가 늘어나지 않으므로 시스템 성능이 저하되는 것을 방지할 수 있다.
ThreadPoolExecutor 로 I/O bound 작업 병렬처리 실험하기
ThreadPoolExecutor는 I/O bound 작업에 유리하다. ThreadPoolExecutor가 여러 작업을 동시에 수행하여 대기 시간을 최소화할 수 있기 때문이다.
I/O bound 작업의 예시로는 다음과 같은 작업이 있다. 우선, 웹에서 데이터를 다운로드 하는 경우 네트워크 I/O(입출력) 에 의해 작업의 성능이 제한되므로 I/O bound 작업에 해당된다. 또한 여러개의 파일을 동시에 읽고 처리하는 작업도 파일 I/O에 해당되므로 I/O bound 작업에 해당한다.
실제로 ThreadPoolExecutor 로 I/O bound 작업의 실행시간을 단축시킬 수 있는지 간단한 실험을 해보기로 한다. 아래는 웹 페이지의 존재 여부를 확인하는 네트워크 I/O bound 작업을 멀티스레딩 없이 실행시켜보는 코드이다.
import time
import requests
import concurrent.futures
# 위키피디아 페이지의 존재 여부를 확인하는 함수
def get_wiki_page_existence(wiki_page_url, timeout=10):
response = requests.get(url=wiki_page_url, timeout=timeout)
page_status = "unknown"
if response.status_code == 200:
page_status = "exists"
elif response.status_code == 404:
page_status = "page not exist"
return wiki_page_url + " - " + page_status
# 50개의 url 에 대해서 확인
wiki_page_urls = ["https://en.wikipedia.org/wiki/" + str(i) for i in range(50)]
print("Running without threads:")
without_threads_start = time.time()
for url in wiki_page_urls:
print(get_wiki_page_existence(wiki_page_url=url))
# 실행 시간 확인
print("Without threads time:", time.time() - without_threads_start)
# Without threads time: 14.567435026168823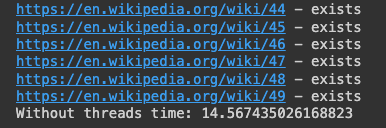
이 경우 약 14.5 초가 걸렸다.
동일한 작업을 ThreadPoolExecutor()를 사용하여 비동기 처리로 수행해보았다.
import time
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
# 위키피디아 페이지의 존재 여부를 확인하는 함수
def get_wiki_page_existence(wiki_page_url, timeout=10):
response = requests.get(url=wiki_page_url, timeout=timeout)
page_status = "unknown"
if response.status_code == 200:
page_status = "exists"
elif response.status_code == 404:
page_status = "does not exist"
return wiki_page_url + " - " + page_status
wiki_page_urls = ["https://en.wikipedia.org/wiki/" + str(i) for i in range(50)]
print("Running without threads:")
threads_start = time.time()
# Thread들로 get_wiki_page_existence 함수를 수행시키기
with ThreadPoolExecutor() as executor:
futures = []
for url in wiki_page_urls:
futures.append(executor.submit(get_wiki_page_existence, wiki_page_url=url))
for future in as_completed(futures):
print(future.result())
# 실행 시간 확인
print("With ThreadPoolExecutor time:", time.time() - threads_start) # With ThreadPoolExecutor time: 6.237553119659424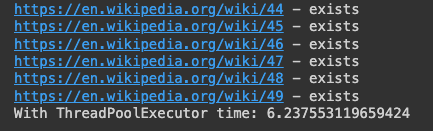
이 경우 약 6.2초가 소요되었으므로 병렬처리를 통해 작업 수행을 최적화할 수 있다는 것을 확인할 수 있었다.
Spark Cluster의 병렬처리와 ThreadPoolExecutor 의 관계
Spark Cluster 에서 ThreadPoolExecutor 를 사용하는 것이 일반적으로 권장되지는 않는다고 한다. Spark는 자체 스케줄링 시스템과 클러스터 관리를 통해 작업을 분산시킨다. 따라서 ThreadPoolExecutor 를 사용하여 스레드 수를 잘못 설정하게 되면 오히려 Spark 어플리케이션의 성능에 부정적인 영향을 줄 수 있다. 너무 많은 thread 수를 주었을 때 컨텍스트 스위칭 비용이 증가하여 성능 저하를 일으킬 수 있으며 너무 적은 thread 수를 주었을 때는 CPU 자원을 충분히 활용하지 못하게 될 수 있다.
Reference
https://docs.python.org/ko/3/library/concurrent.futures.html
concurrent.futures — Launching parallel tasks
Source code: Lib/concurrent/futures/thread.py and Lib/concurrent/futures/process.py The concurrent.futures module provides a high-level interface for asynchronously executing callables. The asynchr...
docs.python.org
https://www.digitalocean.com/community/tutorials/how-to-use-threadpoolexecutor-in-python-3
DigitalOcean | Cloud Hosting for Builders
Simple, scalable cloud hosting solutions built for small and mid-sized businesses.
www.digitalocean.com
'Programming Languages > Python' 카테고리의 다른 글
| Python 으로 코딩테스트 볼 때 유용한 code 정리 (0) | 2023.09.09 |
|---|---|
| [Python] any() 함수 (0) | 2023.06.26 |
| [Python] Conda 설치 및 가상환경 생성 (0) | 2023.05.20 |
| [백준] 1022번: 소용돌이 예쁘게 출력하기 Python (0) | 2023.03.14 |
| [Python] 2차원 배열 90도 회전하기 (시계방향) (0) | 2023.01.13 |
Python 의 GIL (Global Interpreter Lock)
Python은 멀티 스레딩 환경에서 두 개이상의 스레드가 동시에 동일한 자원에 접근하는 것을 방지하기 위해 GIL 매커니즘을 사용한다. GIL에 의해 CPU bound 작업을 처리하는 경우 한번에 하나의 스레드만 실행하도록 동작한다. 반면 I/O bound 작업의 경우에는 I/O 작업 중에 GIL가 해제되기 때문에 GIL의 영향이 상대적으로 적다. 이렇게 하나의 스레드만 사용하게 되는 GIL의 제약사항을 극복하기 위해서 Python에서 threading 과 multiprocessing 을 사용했다. 각 Python 의 프로세스가 자체적인 메모리 공간과 GIL 를 가지므로 여러 CPU 코어를 사용한 병렬처리가 가능하다. 그리고 Python3.2 부터 Concurrent.future 모듈이 등장했다.
Concurrent.future 모듈
Concurrent.futures 모듈은 Python에서 비동기 처리를 할 수 있도록 고수준의 인터페이스를 제공하는 모듈이다. Concurrent.future에는 ThreadPoolExecutor와 ProcessPoolExecutor 라는 두가지 주요한 실행자 클래스가있다. 이 실행자(Executor)는 작업의 실행을 관리하는 객체를 의미한다. 즉, 프로세스 및 스레드 객체를 직접적으로 작성하지 않고도 함수 호출을 객체화 하여 병렬 작업을 실행할 수 있다.
주요 특징
1. Executor
- ThreadPoolExecutor : thread 기반의 병렬실행을 위한 클래스이다. I/O-bound 작업을 병렬로 수행할 때 유용하다.
- ProcessPoolExecutor : Process 기반의 병렬 실행을 위한 클래스이다. CPU-bound 작업을 병렬로 수행할 때 유용하다.
2. Future 객체
Future 객체는 비동기 실행의 결과를 나타낸다. 실행중이거나 완료된 작업에 대한 상태와 결과를 캡슐화한다.
3. 작업 제출 및 결과 처리
- Executor.submit() : 실행할 함수와 파라미터를 실행자(executor)에게 제출(submit)하면 Future 객체가 반환된다.
- Future.result() : 작업의 결과를 Future 객체로부터 얻을 수 있다.
ThreadPool 이란
병렬처리 작업이 많아지게 되면 thread수가 증가하고 새로운 thread 생성과 스케줄링 작업으로 인해 메모리 사용량이 증가한다. 갑자기 병렬작업이 증가하여 시스템 성능이 저하되는 것을 방지하기 위해 Thread Pool 을 사용할 수 있다. ThreadPool은 작업처리에 사용되는 thread를 제한된 개수(ThreadPoolExecutor에서는 max_workers 에 해당한다.)만큼 정하여 pool 에 둔다. 그리고 task queue에 들어와서 대기중인 task 를 thread가 하나씩 처리하게한다. 이렇게 했을 때의 이점은 갑자기 작업이 증가하더라도 thread 의 전체 개수가 늘어나지 않으므로 시스템 성능이 저하되는 것을 방지할 수 있다.
ThreadPoolExecutor 로 I/O bound 작업 병렬처리 실험하기
ThreadPoolExecutor는 I/O bound 작업에 유리하다. ThreadPoolExecutor가 여러 작업을 동시에 수행하여 대기 시간을 최소화할 수 있기 때문이다.
I/O bound 작업의 예시로는 다음과 같은 작업이 있다. 우선, 웹에서 데이터를 다운로드 하는 경우 네트워크 I/O(입출력) 에 의해 작업의 성능이 제한되므로 I/O bound 작업에 해당된다. 또한 여러개의 파일을 동시에 읽고 처리하는 작업도 파일 I/O에 해당되므로 I/O bound 작업에 해당한다.
실제로 ThreadPoolExecutor 로 I/O bound 작업의 실행시간을 단축시킬 수 있는지 간단한 실험을 해보기로 한다. 아래는 웹 페이지의 존재 여부를 확인하는 네트워크 I/O bound 작업을 멀티스레딩 없이 실행시켜보는 코드이다.
import time
import requests
import concurrent.futures
# 위키피디아 페이지의 존재 여부를 확인하는 함수
def get_wiki_page_existence(wiki_page_url, timeout=10):
response = requests.get(url=wiki_page_url, timeout=timeout)
page_status = "unknown"
if response.status_code == 200:
page_status = "exists"
elif response.status_code == 404:
page_status = "page not exist"
return wiki_page_url + " - " + page_status
# 50개의 url 에 대해서 확인
wiki_page_urls = ["https://en.wikipedia.org/wiki/" + str(i) for i in range(50)]
print("Running without threads:")
without_threads_start = time.time()
for url in wiki_page_urls:
print(get_wiki_page_existence(wiki_page_url=url))
# 실행 시간 확인
print("Without threads time:", time.time() - without_threads_start)
# Without threads time: 14.567435026168823이 경우 약 14.5 초가 걸렸다.
동일한 작업을 ThreadPoolExecutor()를 사용하여 비동기 처리로 수행해보았다.
import time
import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
# 위키피디아 페이지의 존재 여부를 확인하는 함수
def get_wiki_page_existence(wiki_page_url, timeout=10):
response = requests.get(url=wiki_page_url, timeout=timeout)
page_status = "unknown"
if response.status_code == 200:
page_status = "exists"
elif response.status_code == 404:
page_status = "does not exist"
return wiki_page_url + " - " + page_status
wiki_page_urls = ["https://en.wikipedia.org/wiki/" + str(i) for i in range(50)]
print("Running without threads:")
threads_start = time.time()
# Thread들로 get_wiki_page_existence 함수를 수행시키기
with ThreadPoolExecutor() as executor:
futures = []
for url in wiki_page_urls:
futures.append(executor.submit(get_wiki_page_existence, wiki_page_url=url))
for future in as_completed(futures):
print(future.result())
# 실행 시간 확인
print("With ThreadPoolExecutor time:", time.time() - threads_start) # With ThreadPoolExecutor time: 6.237553119659424이 경우 약 6.2초가 소요되었으므로 병렬처리를 통해 작업 수행을 최적화할 수 있다는 것을 확인할 수 있었다.
Spark Cluster의 병렬처리와 ThreadPoolExecutor 의 관계
Spark Cluster 에서 ThreadPoolExecutor 를 사용하는 것이 일반적으로 권장되지는 않는다고 한다. Spark는 자체 스케줄링 시스템과 클러스터 관리를 통해 작업을 분산시킨다. 따라서 ThreadPoolExecutor 를 사용하여 스레드 수를 잘못 설정하게 되면 오히려 Spark 어플리케이션의 성능에 부정적인 영향을 줄 수 있다. 너무 많은 thread 수를 주었을 때 컨텍스트 스위칭 비용이 증가하여 성능 저하를 일으킬 수 있으며 너무 적은 thread 수를 주었을 때는 CPU 자원을 충분히 활용하지 못하게 될 수 있다.
Reference
https://docs.python.org/ko/3/library/concurrent.futures.html
concurrent.futures — Launching parallel tasks
Source code: Lib/concurrent/futures/thread.py and Lib/concurrent/futures/process.py The concurrent.futures module provides a high-level interface for asynchronously executing callables. The asynchr...
docs.python.org
https://www.digitalocean.com/community/tutorials/how-to-use-threadpoolexecutor-in-python-3
DigitalOcean | Cloud Hosting for Builders
Simple, scalable cloud hosting solutions built for small and mid-sized businesses.
www.digitalocean.com
'Programming Languages > Python' 카테고리의 다른 글
| Python 으로 코딩테스트 볼 때 유용한 code 정리 (0) | 2023.09.09 |
|---|---|
| [Python] any() 함수 (0) | 2023.06.26 |
| [Python] Conda 설치 및 가상환경 생성 (0) | 2023.05.20 |
| [백준] 1022번: 소용돌이 예쁘게 출력하기 Python (0) | 2023.03.14 |
| [Python] 2차원 배열 90도 회전하기 (시계방향) (0) | 2023.01.13 |