

현 회사에서 데이터 엔지니어링 프로젝트를 위해 Databricks 플랫폼을 구축하고 파이프라인을 개발하는 일을 담당하고 있다. Databricks의 기능에 대해 한국어로 잘 정리된 기술 블로그가 보이지 않아서, Databricks를 어떻게 하면 제대로 쓸 수 있을지 투고해보려고 한다.
Databricks 플랫폼에서 데이터 카탈로그에 해당하는 Unity Catalog 에 대해 정리해보려고 한다.
데이터 카탈로그 , 그 이전에 데이터 가버넌스
우선 데이터 가버넌스라는 개념은 조직 내에 데이터 자산의 품질, 보안, 접근성, 일관성을 관리하고 제어하는 정책들을 말한다. 데이터 가버넌스에는 다음과 같은 활동들이 있다.
- 데이터 표준과 정책 설정
- 데이터 품질 관리
- 데이터 및 개인 정보 보호
- 데이터 관리에 대한 책임 및 역할에 대한 정의
- 데이터 카탈로그란 무엇인가
데이터 카탈로그
데이터 카탈로그는 메타데이터를 사용하여 조직의 데이터 자산을 관리하는 플랫폼을 말한다. 조직 내부에는 데이터에 접근하여 사용하는 여러 팀들이 있을 것이고 이들 팀에 대해 액세스를 관리하고, 데이터 자산의 일관성을 유지시켜야 할 것이다. 데이터 카탈로그를 통해서 데이터 자산을 중복을 피하고 재사용할 수 있으며, 데이터 검색과 액세스를 효율적으로 해결할 수 있다. 그리고 이러한 데이터 카탈로그에 해당 하는 기능이 데이터브릭스에서 unity catalog 에 해당한다.
Unity Catalog 의 역할
데이터 브릭스에서 한 리전에 여러개의 Workspace 를 만들 수 있다. 예를 들어 AWS 를 사용한다면 서울 리전에 개발 환경의 dev-workspace와 프로덕션 환경의 prod-workspace 2개를 각각 만들 수 있다.
Unity Catalog 를 사용하지 않는 기존의 (legacy) Workspace 개념에서는 한 workspace 에 대한 메타데이터를 hive metastore에서 관리한다. 데이터브릭스에서도 Hive 엔진을 사용한다. Hive는 하둡 에코시스템에서 SQL 와 유사한 HiveQL 을 사용하여 대규모 데이터를 처리한다. 그리고 Hive Metastore 는 HDFS 에 저장된 Hive Table의 테이블, 컬럼 정보, 파티션 정보 등 메타데이터를 저장하는 공간이다. 데이터브릭스에서도 workspace 를 생성하면 기본적으로 hive_metastore 라는 저장공간이 생기게 된다.
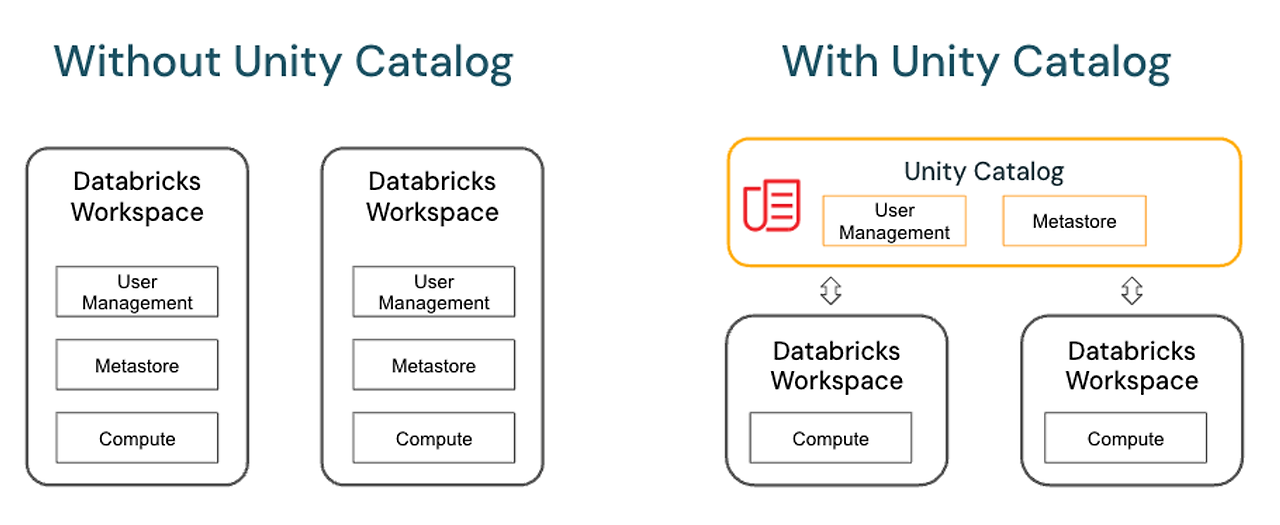
그런데 같은 리전에 해당하는 workspace 를 중앙 집중형으로 관리하고 싶다면 어떻게 해야할까? hive_metastore 는 하나의 workspace에 종속되는 개념이므로, dev-workspace에서의 데이터에 prod-workspace가 접근할 수 없을 것이다. 이를 가능하게 해주는 것이 Unity Catalog라는 개념이다. Unity Catalog 는 Workspace 상위의 개념에서, Unity Catalog 기능을 활성화 하는 경우 한 리전의 Workspace들의 metadata를 하나의 Metastore에서 관리한다.
즉, Metastore 와 hive_metastore 는 실제로 메타데이터 관리라는 유사한 기능을 하지만 적용되는 범위가 다르다 !
Unity Catalog 활성화를 위한 Metastore
참고로 Unity Catalog 사용을 위한 Metastore 는 Databricks Account Console 당 한 리전에 한개만 생성할 수 있다. Metastore 의 계층 구조를 살펴보면 좀 더 이해가 쉽다.
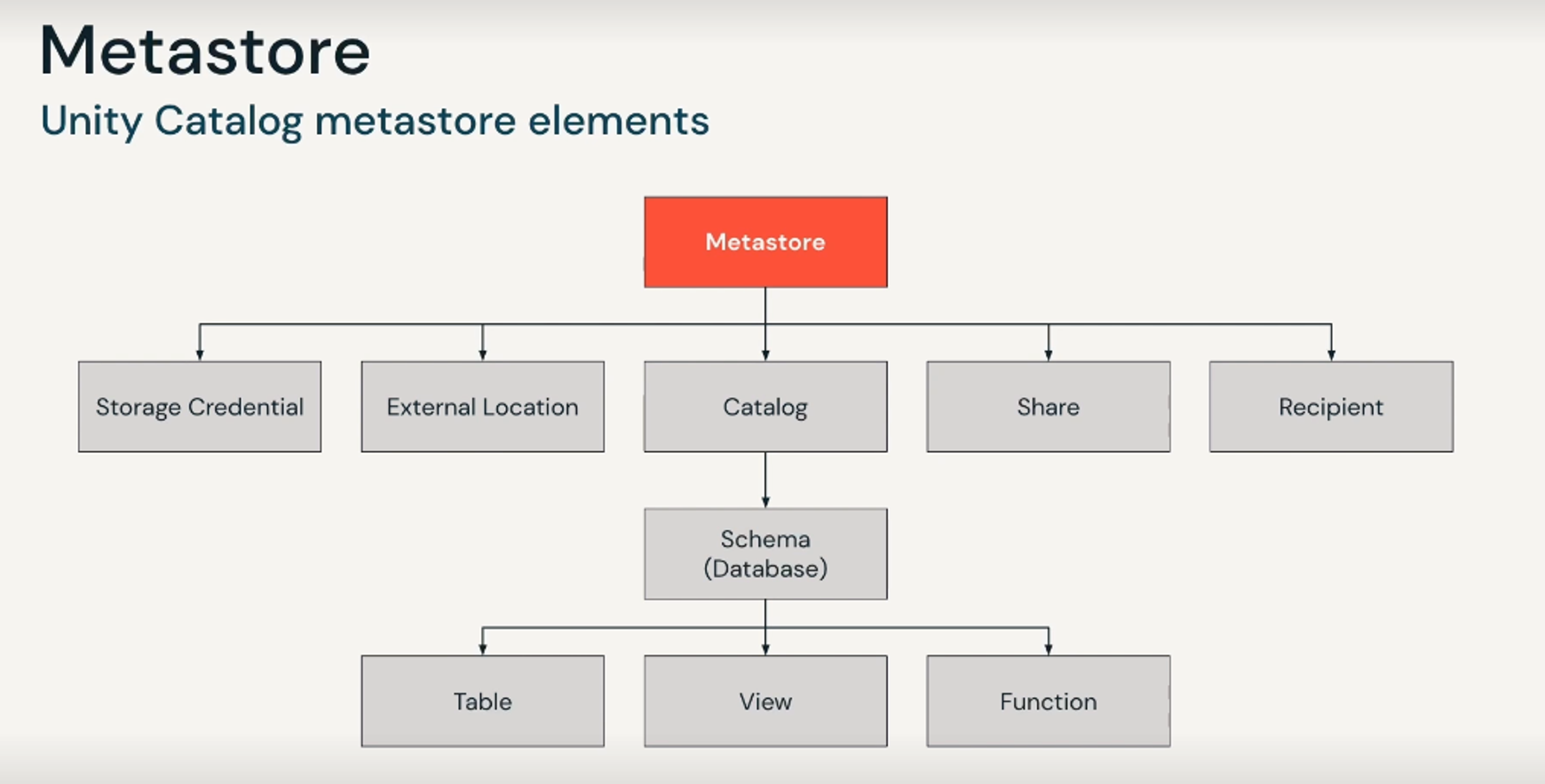
Metastore라는 상위의 개념이 하위의 storage credential 방식 및 external location 으로 등록된 외부 클라우드 저장공간, Catalog 등의 계보 및 메타데이터를 관리한다. Catalog 는 Schema (Database) 보다 상위의 개념이다. Unity Catalog 를 활성화 한 workspace에서 아래와 같이 DDL 로 Catalog를 생성할 수 있다.
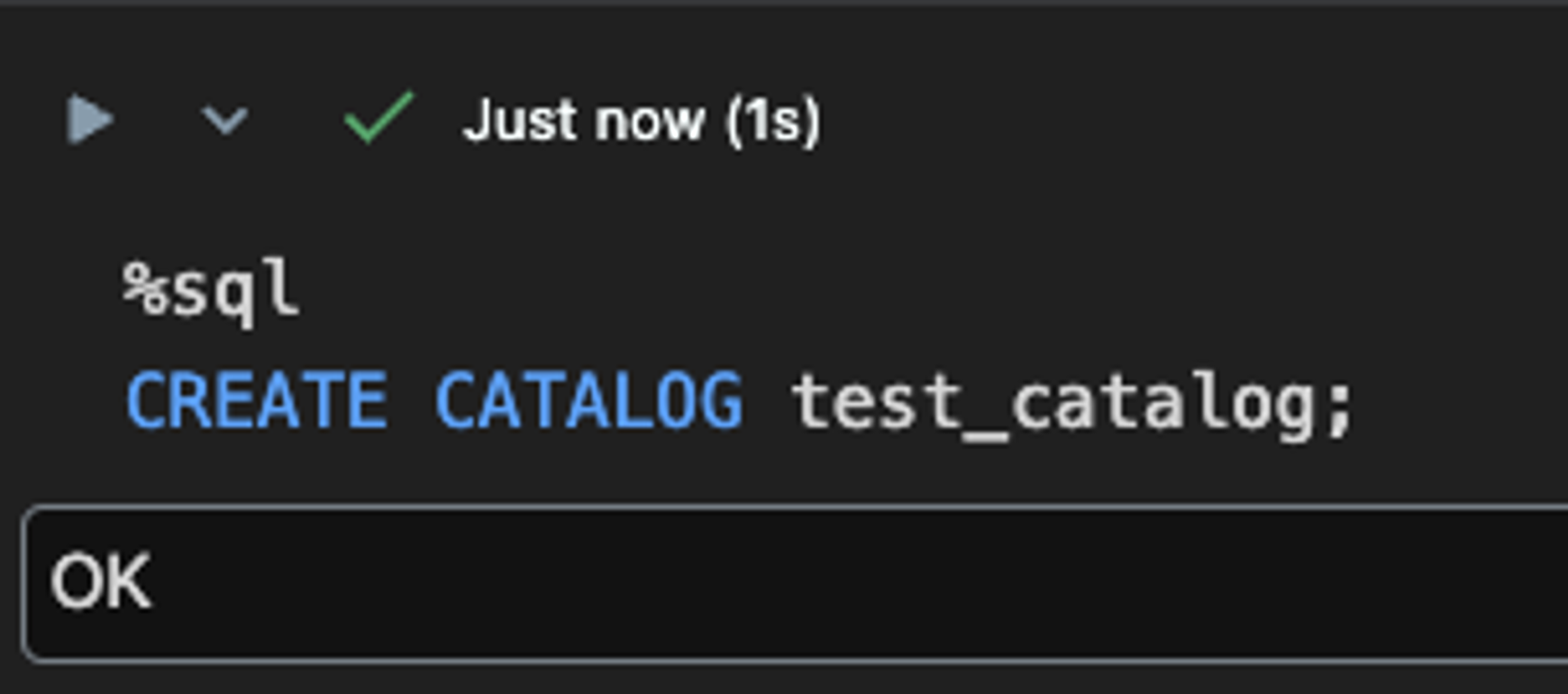
생성된 Catalog는 Workspace의 Catalog Explore 라는 탭에서 확인할 수 있다. Catalog를 생성하면 default schema와 information_schema가 자동으로 생성된다.

참고로 'System' Catalog의 information_schema 는 Unity Catalog에서 생성된 모든 Catalog에 제공되며, metastore에 속한 모든 catalog들에 대한 정보를 확인할 수 있다.
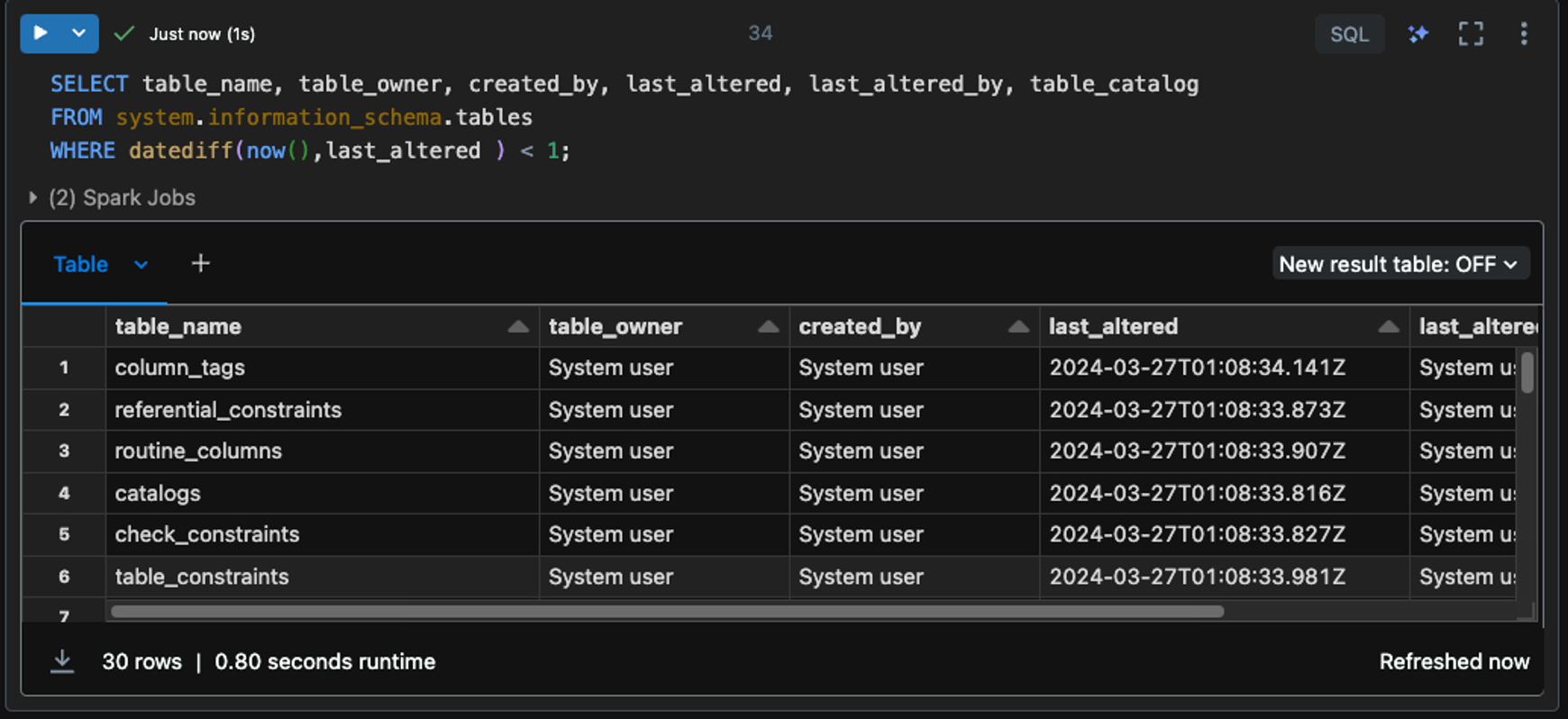
Catalog를 선택 후, 하위의 Schema 또한 아래와 같이 Databricks SQL 문으로 생성할 수 있다.
Catalog를 사용하는 경우 전통적인 SQL 과 다르게 three-level namespace를 사용한다.
예를 들어서 기존의 SQL 에서는 아래와 같이 two-level namespace를 사용한다.
SELECT * FROM schema.tableCatalog 는 한 계층이 더 추가되므로 아래와 같이 조회할 수 있다.
SELECT * FROM catalog.schema.table또한 Metastore > Catalog > Schema > Table 계층에서, 하위에 있는 Object는 상위 Object의 권한을 상속받는다. 예를 들어 Catalog 하위에 있는 Table은 Catalog에서 허용되는 권한을 상속받아서 사용할 수 있다.
Conclusion
Delta Lake 에서 중앙 관리형 데이터 거버넌스를 제공하는 Unity Catalog 개념에 대해 살펴보았다. Cloud 기반의 데이터 플랫폼을 구성해서 사용한다면, cloud 특성상 다양한 cloud 서비스들에 대해 cross-platform 하게 사용하게 될 수도 있을 것이다. 이에 대해 다양한 cloud storage 에 저장되는 대용량의 데이터를 하나의 metastore에서 관리를 할 수 있으므로 장점이 될 것 같다.
Reference
- https://aws.amazon.com/ko/what-is/data-catalog/
- Databricks Data Engineering Course
'Data Engineering > Databricks & Delta Lake' 카테고리의 다른 글
| MLOps 파이프라인 설계 및 MLflow 활용 방법 (0) | 2024.11.24 |
|---|---|
| [Databricks] Delta Live Table 로 파이프라인 개발 & 데이터 퀄리티 모니터링하기 (0) | 2024.04.14 |
| [TIL] Delta Table에 upsert 하기 (0) | 2024.02.14 |
| [Databricks] 데이터브릭스 무료 버전 사용하는 방법 (Databricks Community Edition) (0) | 2023.10.29 |
| [AWS/Databricks] Databricks Workspace Private Link로 구성하기 - Private Link를 사용해야 하는 이유 & VPC Endpoint 유형 (0) | 2023.07.03 |