
kakfa의 등장 배경
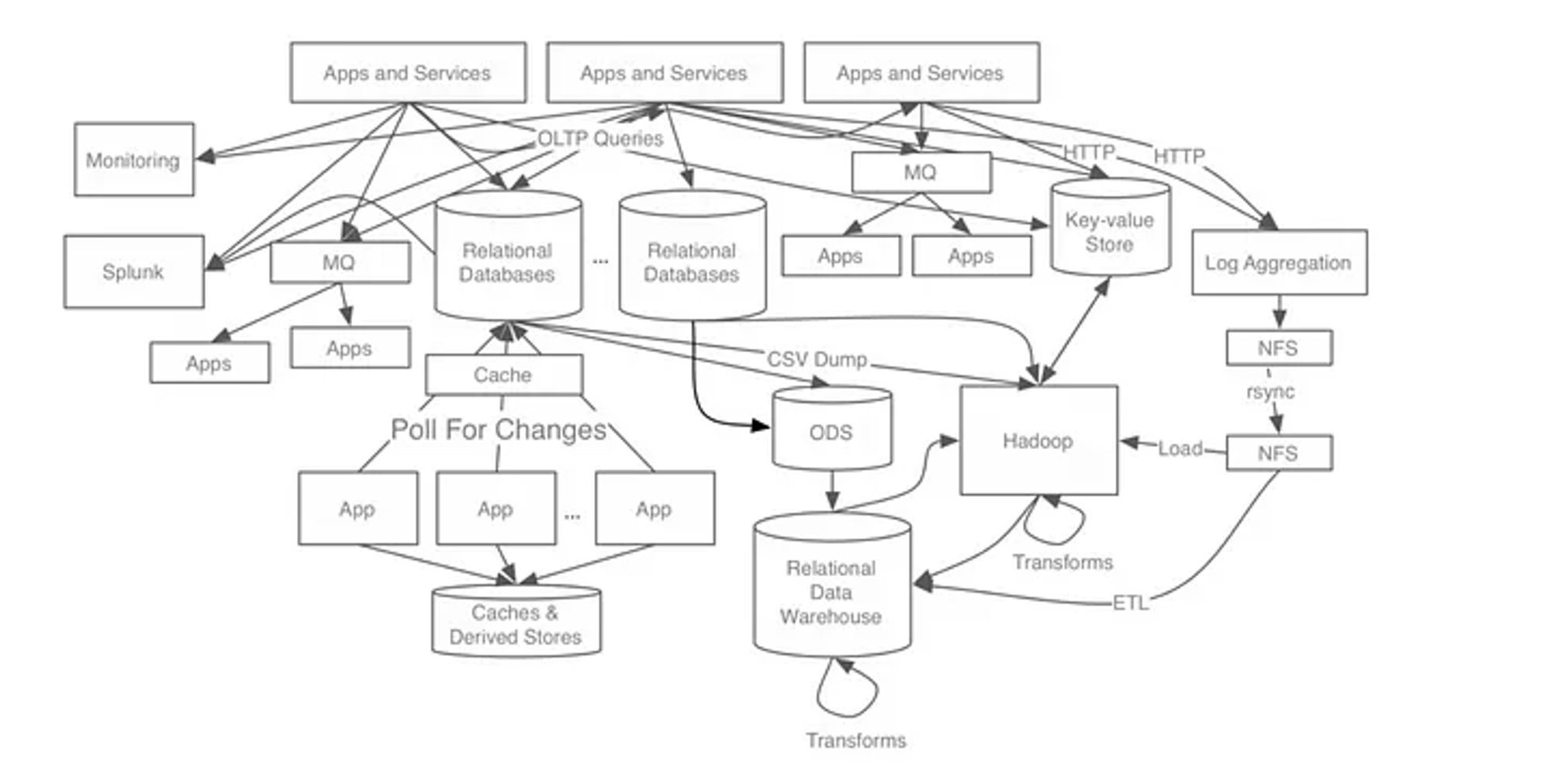
실시간으로 데이터를 처리하는 과정에서, 다수의 producer 와 consumer가 개별적인 연결을 맺는 구조의 경우 하나의 시스템만 추가되어도 통신 구조가 복잡해진다. 이런 문제를 해결하기 위해서 카프카를 통해, 메세지와 데이터의 흐름을 중앙화하여 관리한다.
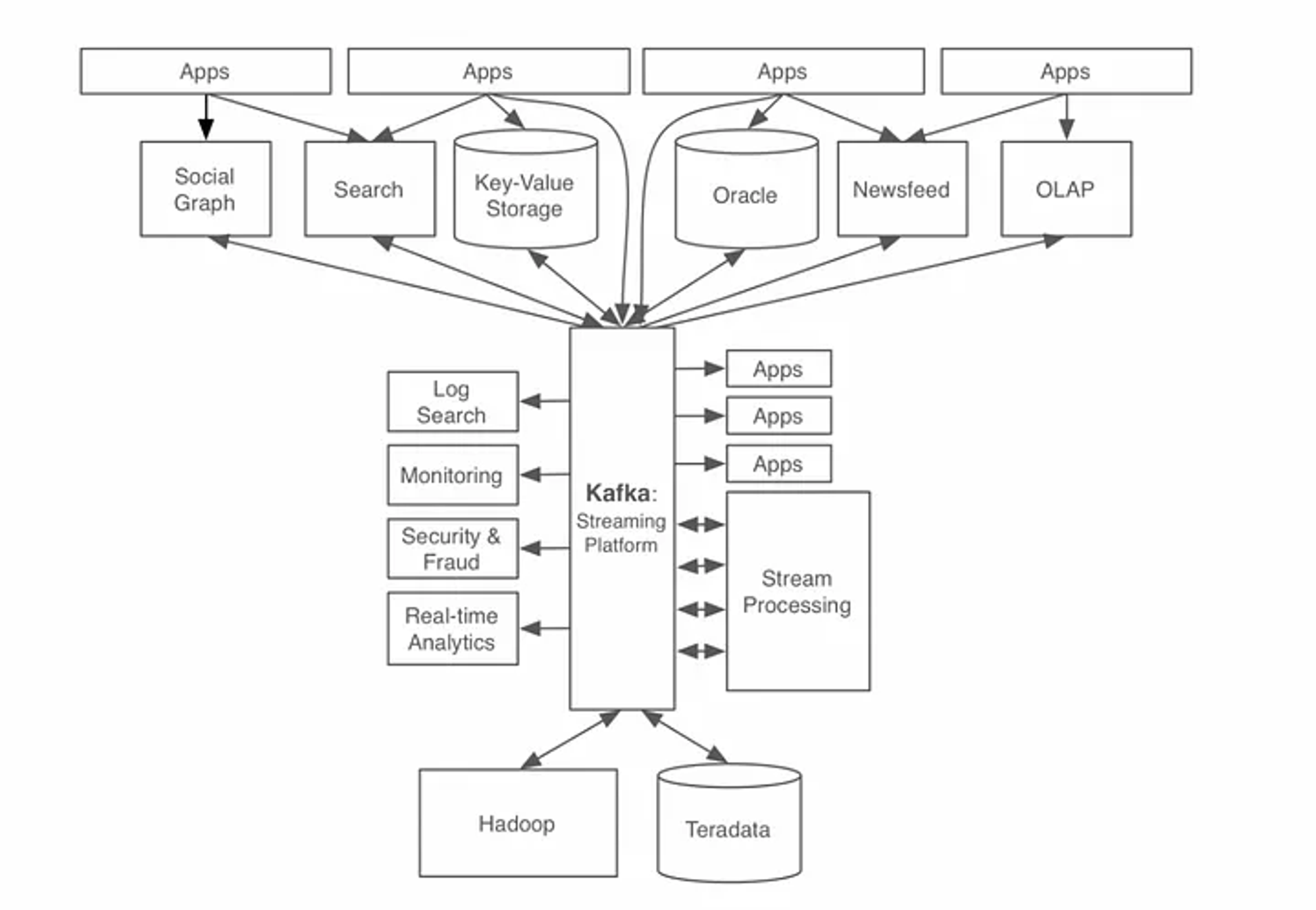
Kafka 의 구성요소
- producer : 정보를 제공하는 process
- consumer: 정보를 제공받아서 사용하려는 process
- consumer group : 카프카 컨슈머들은 컨슈머 그룹에 속한다. 여러개의 컨슈머가 같은 컨슈머 그룹에 속할 때 각 컨슈머가 해당 토픽의 다른 파티션을 분담해서 메세지를 읽을 수 있다.
- broker : 데이터를 저장하고 수신 및 전달하는 node (그림은 MQ == Broker 같이 보이는데 둘은 다른 개념이다)
- message queue : producer 의 데이터를 받아서 임시저장하고 consumer에 저장하는 공간. message 는 endpoint 간 직접 통신하지 않고, queue를 통해 중개 된다.
- topic: 카프카에서 데이터를 구분하는 가장 기본적인 단위이다. 하나의 토픽은 여러개의 파티션으로 구성된다. 토픽에 producer 가 데이터를 넣고 컨슈머가 토픽에서 데이터를 가져간다.
Kafka 와 Zookeeper
- Kafka를 실행하기 위해 Zookeeper가 필요하다. 그러나 최신 버전의 Kafka에서는 Zookeeper 없이도 실행할 수 있는 KRaft 모드가 도입되었다.
- Zookeeper : Kafka 클러스터의 메타데이터를 관리하고, 브로커의 상태를 모니터링한다. Kafka Broker 는 Zookeeper와 통신하여 메타데이터와 클러스터 상태를 관리한다.
- KRaft : Zookeeper 없이 Kafka 자체적으로 메타데이터와 클러스터 상태를 관리한다. Zookeeper 기반 Kafka에 비해서 시스템이 단순해지고, 운영 오버헤드가 줄어든다.
Kafka의 장점
- 비동기 처리를 할 수 있다.
- 어플리케이션과 분리되므로 결합도가 낮다.
- producer / consumer 서비스를 확장할 수 있다.
- consumer 가 다운되더라도 어플리케이션이 중단되지 않으며, MQ에 메세지가 남아있다.
- MQ에 들어가면 메세지가 consumer 들에게 전달되는 것을 보장한다.
Docker Compose 로 실습환경 구축하기
- Mac M2 환경에서 실습했기 때문에 platform 부분을 명시적으로 linux/amd64 로 지정해주었습니다.
version: '3'
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
- SERVICE_PRECONDITION=namenode:9870
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: resourcemanager
restart: always
environment:
- SERVICE_PRECONDITION=namenode:9000,namenode:9870,datanode:9864
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: nodemanager
restart: always
environment:
- SERVICE_PRECONDITION=namenode:9000,namenode:9870,datanode:9864,resourcemanager:8088
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: historyserver
restart: always
environment:
- SERVICE_PRECONDITION=namenode:9000,namenode:9870,datanode:9864,resourcemanager:8088
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
platform: linux/amd64
ports:
- "2181:2181"
environment:
- ZOOKEEPER_ID=1
- ZOOKEEPER_SERVER_1=zookeeper:2888:3888
kafka1:
image: confluentinc/cp-kafka:6.0.1
platform: linux/amd64
container_name: kafka1
ports:
- "9092:9092"
environment:
- KAFKA_BROKER_ID=1
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka1:9092
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- kafka1_data:/var/lib/kafka/data
kafka2:
image: confluentinc/cp-kafka:6.0.1
platform: linux/amd64
container_name: kafka2
ports:
- "9093:9092"
environment:
- KAFKA_BROKER_ID=2
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka2:9093
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- kafka2_data:/var/lib/kafka/data
kafka3:
image: confluentinc/cp-kafka:6.0.1
platform: linux/amd64
container_name: kafka3
ports:
- "9094:9092"
environment:
- KAFKA_BROKER_ID=3
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka3:9094
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- kafka3_data:/var/lib/kafka/data
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:
kafka1_data:
kafka2_data:
kafka3_data:
1. docker compose 로 서비스를 background에서 실행시킨다.
$ docker-compose up -d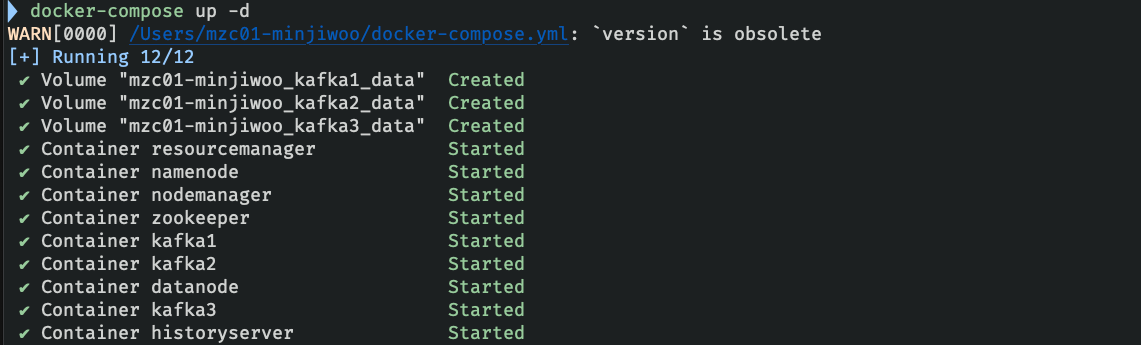
2. kafka 컨테이너 내부로 접속한다.
$ docker exec -it kafka1 /bin/bash
3. kafka 컨테이너에서 topic을 생성한다.
# kafka1 container 내부
$ kafka-topics --create --topic test-topic --bootstrap-server kafka1:9092 --replication-factor 3 --partitions 1- -create: 토픽 생성 명령어
- -topic my-topic: my-topic라는 이름의 토픽 생성
- -partitions 1: 토픽의 파티션 수
- -replication-factor 1: 토픽의 복제 팩터
- -bootstrap-server localhost:9092: Kafka 브로커의 부트스트랩 서버 지정

4. 터미널 탭을 하나 더 열어서 다시 kafka container 에 접속한다.
$ docker exec -it kafka1 /bin/bash
5. kafka consumer 를 실행시켜서 message를 topic 으로부터 읽는다.
$ kafka-console-consumer --topic test-topic --bootstrap-server kafka1:9092 --from-beginning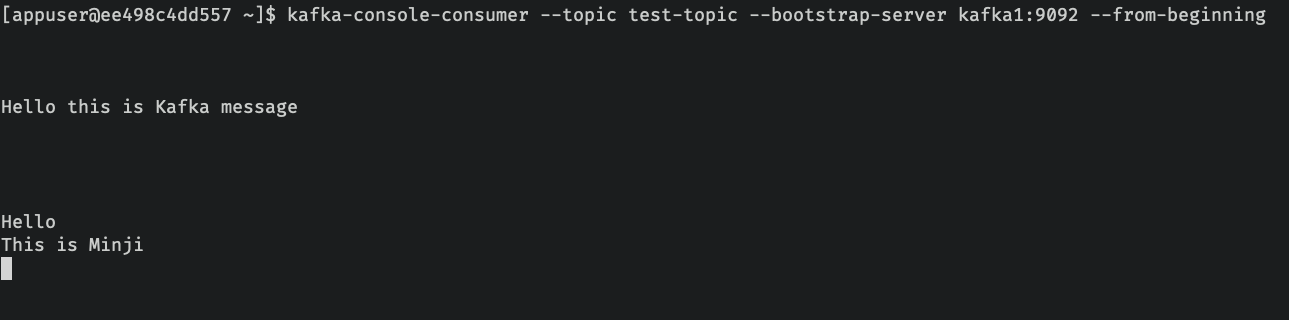
Trouble Shooting
초기에는 kafka container 를 1개만 생성했었다. 이때 kafka 에서 topic 을 생성하고, producer 를 통해 message를 넣는 것까지는 되었으나 consumer 가 구독해서 메세지를 읽어오지 못하는 문제가 있었다.
$ docker logs 명령어를 통해 로그를 살펴보니, 다음과 같았다.

replication factor 가 3개 이므로 broker (kafka container) 의 개수를 물리적으로 3개 이상 구성해 주어야 한다는 에러이다. 실제로 docker-compose file 의 kafka container 를 3개로 생성해준 이후 문제가 해결되었다.
kafka 클러스터가 반드시 3개 이상의 브로커를 구성해주어야 하는 것은 아니지만, 일반적으로 고가용성 및 데이터 내구성을 보장하기 위해서 3개 이상의 브로커를 사용하는 것이 권장된다고 한다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| Docker Compose 로 Hadoop 클러스터와 Presto 엔진 구축하기 (0) | 2024.06.16 |
|---|
kakfa의 등장 배경
실시간으로 데이터를 처리하는 과정에서, 다수의 producer 와 consumer가 개별적인 연결을 맺는 구조의 경우 하나의 시스템만 추가되어도 통신 구조가 복잡해진다. 이런 문제를 해결하기 위해서 카프카를 통해, 메세지와 데이터의 흐름을 중앙화하여 관리한다.
Kafka 의 구성요소
- producer : 정보를 제공하는 process
- consumer: 정보를 제공받아서 사용하려는 process
- consumer group : 카프카 컨슈머들은 컨슈머 그룹에 속한다. 여러개의 컨슈머가 같은 컨슈머 그룹에 속할 때 각 컨슈머가 해당 토픽의 다른 파티션을 분담해서 메세지를 읽을 수 있다.
- broker : 데이터를 저장하고 수신 및 전달하는 node (그림은 MQ == Broker 같이 보이는데 둘은 다른 개념이다)
- message queue : producer 의 데이터를 받아서 임시저장하고 consumer에 저장하는 공간. message 는 endpoint 간 직접 통신하지 않고, queue를 통해 중개 된다.
- topic: 카프카에서 데이터를 구분하는 가장 기본적인 단위이다. 하나의 토픽은 여러개의 파티션으로 구성된다. 토픽에 producer 가 데이터를 넣고 컨슈머가 토픽에서 데이터를 가져간다.
Kafka 와 Zookeeper
- Kafka를 실행하기 위해 Zookeeper가 필요하다. 그러나 최신 버전의 Kafka에서는 Zookeeper 없이도 실행할 수 있는 KRaft 모드가 도입되었다.
- Zookeeper : Kafka 클러스터의 메타데이터를 관리하고, 브로커의 상태를 모니터링한다. Kafka Broker 는 Zookeeper와 통신하여 메타데이터와 클러스터 상태를 관리한다.
- KRaft : Zookeeper 없이 Kafka 자체적으로 메타데이터와 클러스터 상태를 관리한다. Zookeeper 기반 Kafka에 비해서 시스템이 단순해지고, 운영 오버헤드가 줄어든다.
Kafka의 장점
- 비동기 처리를 할 수 있다.
- 어플리케이션과 분리되므로 결합도가 낮다.
- producer / consumer 서비스를 확장할 수 있다.
- consumer 가 다운되더라도 어플리케이션이 중단되지 않으며, MQ에 메세지가 남아있다.
- MQ에 들어가면 메세지가 consumer 들에게 전달되는 것을 보장한다.
Docker Compose 로 실습환경 구축하기
- Mac M2 환경에서 실습했기 때문에 platform 부분을 명시적으로 linux/amd64 로 지정해주었습니다.
version: '3'
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: namenode
restart: always
ports:
- 9870:9870
- 9000:9000
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: datanode
restart: always
volumes:
- hadoop_datanode:/hadoop/dfs/data
environment:
- SERVICE_PRECONDITION=namenode:9870
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: resourcemanager
restart: always
environment:
- SERVICE_PRECONDITION=namenode:9000,namenode:9870,datanode:9864
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: nodemanager
restart: always
environment:
- SERVICE_PRECONDITION=namenode:9000,namenode:9870,datanode:9864,resourcemanager:8088
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
platform: linux/amd64
container_name: historyserver
restart: always
environment:
- SERVICE_PRECONDITION=namenode:9000,namenode:9870,datanode:9864,resourcemanager:8088
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
platform: linux/amd64
ports:
- "2181:2181"
environment:
- ZOOKEEPER_ID=1
- ZOOKEEPER_SERVER_1=zookeeper:2888:3888
kafka1:
image: confluentinc/cp-kafka:6.0.1
platform: linux/amd64
container_name: kafka1
ports:
- "9092:9092"
environment:
- KAFKA_BROKER_ID=1
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka1:9092
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- kafka1_data:/var/lib/kafka/data
kafka2:
image: confluentinc/cp-kafka:6.0.1
platform: linux/amd64
container_name: kafka2
ports:
- "9093:9092"
environment:
- KAFKA_BROKER_ID=2
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka2:9093
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- kafka2_data:/var/lib/kafka/data
kafka3:
image: confluentinc/cp-kafka:6.0.1
platform: linux/amd64
container_name: kafka3
ports:
- "9094:9092"
environment:
- KAFKA_BROKER_ID=3
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka3:9094
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=PLAINTEXT:PLAINTEXT
- KAFKA_INTER_BROKER_LISTENER_NAME=PLAINTEXT
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
volumes:
- kafka3_data:/var/lib/kafka/data
volumes:
hadoop_namenode:
hadoop_datanode:
hadoop_historyserver:
kafka1_data:
kafka2_data:
kafka3_data:
1. docker compose 로 서비스를 background에서 실행시킨다.
$ docker-compose up -d2. kafka 컨테이너 내부로 접속한다.
$ docker exec -it kafka1 /bin/bash
3. kafka 컨테이너에서 topic을 생성한다.
# kafka1 container 내부
$ kafka-topics --create --topic test-topic --bootstrap-server kafka1:9092 --replication-factor 3 --partitions 1- -create: 토픽 생성 명령어
- -topic my-topic: my-topic라는 이름의 토픽 생성
- -partitions 1: 토픽의 파티션 수
- -replication-factor 1: 토픽의 복제 팩터
- -bootstrap-server localhost:9092: Kafka 브로커의 부트스트랩 서버 지정
4. 터미널 탭을 하나 더 열어서 다시 kafka container 에 접속한다.
$ docker exec -it kafka1 /bin/bash
5. kafka consumer 를 실행시켜서 message를 topic 으로부터 읽는다.
$ kafka-console-consumer --topic test-topic --bootstrap-server kafka1:9092 --from-beginning
Trouble Shooting
초기에는 kafka container 를 1개만 생성했었다. 이때 kafka 에서 topic 을 생성하고, producer 를 통해 message를 넣는 것까지는 되었으나 consumer 가 구독해서 메세지를 읽어오지 못하는 문제가 있었다.
$ docker logs 명령어를 통해 로그를 살펴보니, 다음과 같았다.
replication factor 가 3개 이므로 broker (kafka container) 의 개수를 물리적으로 3개 이상 구성해 주어야 한다는 에러이다. 실제로 docker-compose file 의 kafka container 를 3개로 생성해준 이후 문제가 해결되었다.
kafka 클러스터가 반드시 3개 이상의 브로커를 구성해주어야 하는 것은 아니지만, 일반적으로 고가용성 및 데이터 내구성을 보장하기 위해서 3개 이상의 브로커를 사용하는 것이 권장된다고 한다.
'Data Engineering > Hadoop' 카테고리의 다른 글
| Docker Compose 로 Hadoop 클러스터와 Presto 엔진 구축하기 (0) | 2024.06.16 |
|---|